Hadoop
Apache Hadoop 是一款支援數據密集型分布式應用程式並以 Apache 2.0 許可協定發布的開源軟體框架。它支援在商用硬體構建的大型叢集上運行的應用程式。Hadoop 是根據 Google 公司發表的 MapReduce 和 Google 檔案系統的論文自行實作而成。
技术体系
- HDFS 分布式文件系统
- YARN 分布式资源调度系统
- MapReduce 分布式计算系统
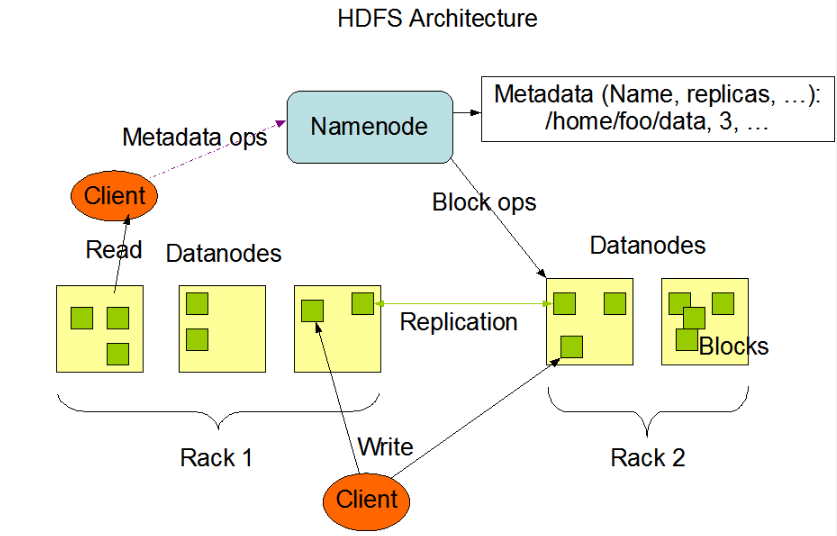
HDFS
Hadoop Distributed File System
由集群机器组成,每个机器部署一个 DataNode 进程,管理部分数据,如果有机器部署了 NameNode,可以理解为负责 HDFS 集群的进程
- 节点
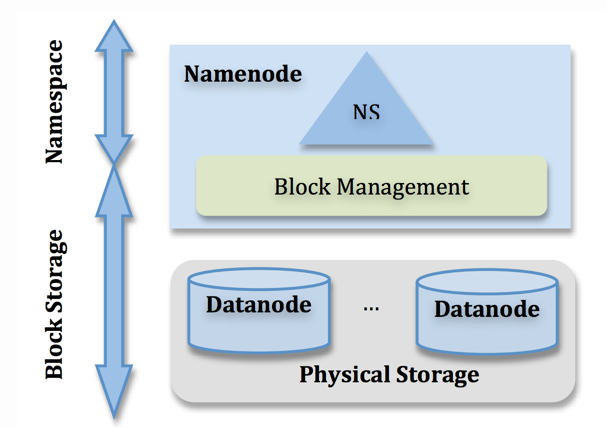
- NameNode 管理者负责命名空间,CRUD 文件及目录,也负责对具体 DataNode 的映射,不负责存储用户数据
- DataNode 文件存储者
- Client 分布式文件系统的应用程序
- MapReduce
负责将任务拆分为多个子任务进行
- JobTracker 总经理进程-分配任务
- TaskTracker 任务监控进程
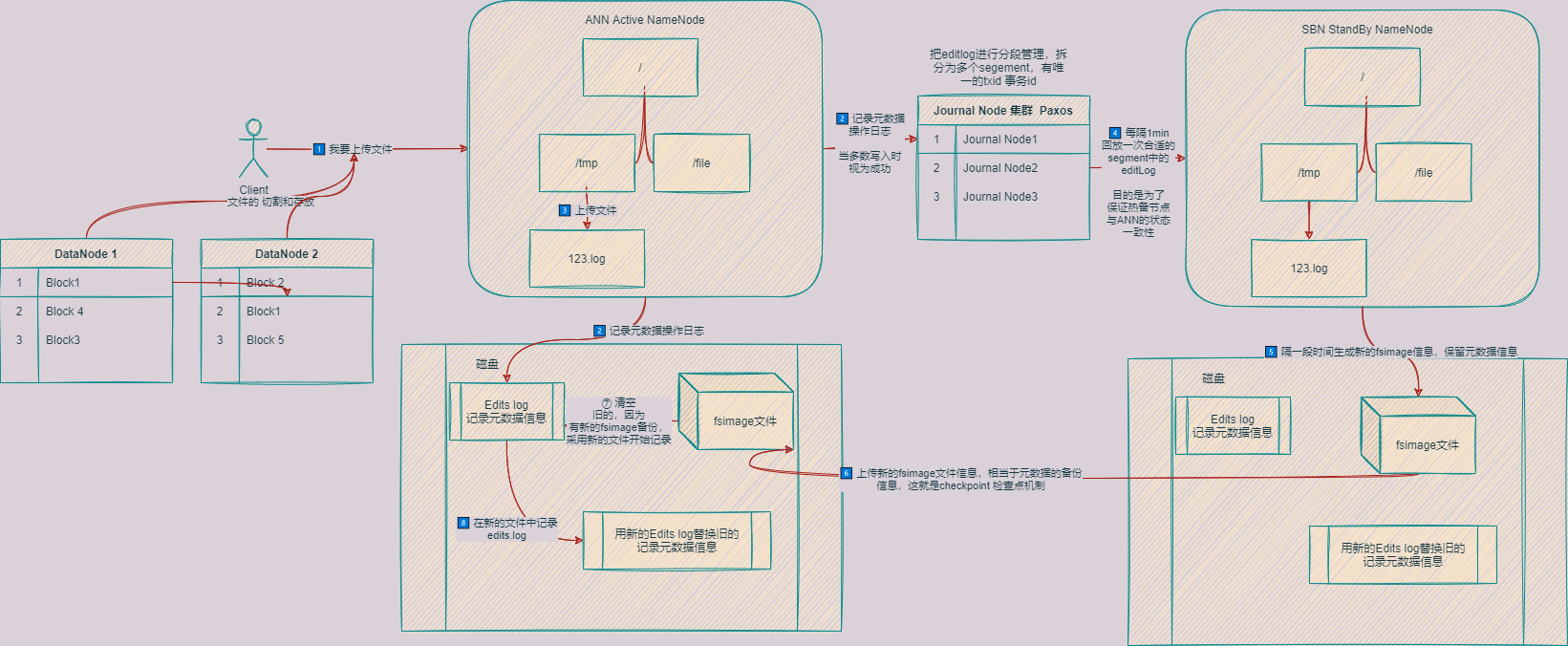
NameNode原理
NameNode首先有namespace,管理整个元数据信息,像文件目录树,权限设置,副本数Etc.
graph TD;
title[NameNode添加文件流程1]
/-->/user
/-->/tmp
/tmp-->/file
hdfs客户端-->|我要导入新的文件123.log| NameNode
/file-->|新建123.log文件对象| 123.log
NameNode-->|创建好了目录的元数据信息| 123.log
关于上述文件目录,平常是基于内存保存的,断电保存是如何实现的呢?
通过周期Flush到持久化设备FsImage文件上,每次重启时会从持久化设备中读取FsImage用于构建Namespace。
而在上面构建的过程中,为了避免频繁的IO读写,通过edits.log日志的形式进行实现,需要恢复时,以磁盘文件为基准,再回放edits.log文件就可以快速恢复,避免了频繁的读写
graph TD;
title[NameNode添加文件流程1]
/-->/user
/-->/tmp
/tmp-->/file
hdfs客户端-->|我要导入新的文件123.log| NameNode
/file-->|新建123.log文件对象| 123.log
NameNode-->|将新建文件的动作记录到editslog中| edits.log
edits.log-->|创建好了目录的元数据信息| 123.log
但是随着时间的增长,edits.log也会变得极其臃肿庞大,如何避免这个问题?
就要引入fsimage/JournalNodes集群/Standby NameNode来把edits.log缩减
大文件的存放涉及到文件的切分,引入了BlockManager进行管理
首先将大文件进行切分为多个Block,每个block 128MB,切分后存放到不同的机器上的DataNode,此外为了保证高可用,Block还默认有2个备份,存放在不同的机器上,这样子恢复时,可以从其他机子进行恢复文件