缓存
缓存常见架构
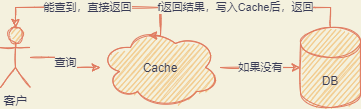
缓存常见问题
缓存穿透
请求缓存和数据库都不存在的数据,那么一定会穿过缓存,去请求数据库,导致数据库压力巨大
缓存空值
解决方法一:缓存空值,适用于少量重复度较高的 key,这样子也不需要缓存大量的无用数据,减少损耗
graph TD;
people--> | 1.查询不存在的key比如nonKey1|Cache
Cache --> |2.可以将常见的一些查询key的值设为null 缓存起来 nonKey1=null | Cache
people2--> |3.再次查询不存在的nonKey1| Cache
Cache --> |4.直接返回null 不会发生缓存穿透| people2
title[缓存空值]
BloomFilter 布隆鸟过滤器
类似于 hbase set 判断元素是否在集合中,在大数据里面有判断数据是否在磁盘,在登录层可以用于判断客户手机号是否存在。
大致原理是通过多次 hash 找到最终的桶们存放进去,置为 1
比如说:现在 15、20、25、30 四个桶是 1 的,现在有一个客户过来查询,经 hash 后结果是 15、20、25,我们可以发现三个桶都是 1 的,那我们就可以估计他应该是在系统里面有登记的。
就算有误判也没关系,因为本身布隆过滤器的过滤粒度效果已经很喜人了。
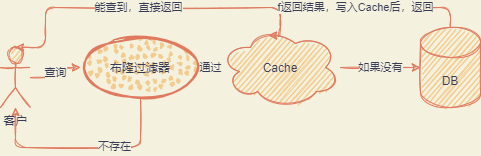
适用于大量无意义无重复的 key 查询,这样子不需要耗费缓存去存放这些垃圾数据,又能过滤掉攻击或者无意义的请求
缓存击穿
大量请求同个 key 时,缓存的 key 失效了,导致大量的流量请求到数据库,导致宕机
解决方案:
当缓存失效时,查询数据库的动作只能由一个请求来实现,可以通过分布式锁来互斥锁住,这样子数据库不受影响。
但问题在于这样子业务会在 key 失效时,吞吐量下降,需要衡量业务的场景。
缓存雪崩
大量的 key 在同一时间同时失效,或者缓存宕机了,导致大量请求涌入数据库,宕机
缓存架构
使用集群缓存,保证高可用。比如 Redis 的两套模式:主从+哨兵 、 Redis Cluster 模式
缓存模式
本地可以使用 ehcache 本地缓存模式,这样子相当于多一个备份,能维持一阵子系统可用性
在流量控制上,可以考虑使用 Hystrix 限流&降级使用,避免 MySQL 宕机
宕机恢复
Redis 持久化、扩容等,尽快恢复 Redis 集群的可用性
热点数据集体失效
设置缓存失效时间时,除了预设的失效时间外,再加入一定的随机变量,这样子避免了集体失效,查询数据库重新刷入时,也可以分批地进行查询回刷,防止流量过大。
Redis事务
通过multi、exec、watch一组命令的组合,做多个命令的一次执行,保证事务性
执行事务时,会按串行化执行队列命令,这段时间其他请求不会插入到命令中
以上就具备了常说ACID里面的原子性A、一致性C和隔离性I,如果开启了AOF机制,并且appendfsync为always,能保证事务具有持久性D
watch命令
是一个乐观锁,主要通过了CAS check and set的机制,来监控对应的值是否变更,继而是让事务能够顺序执行下去
redis分区
Hash
- 好处
- 直接通过hash将key-value放到位置
- 缺点
- 但如果需要扩容时,就会导致所有原本节点的数据都需要做重新迁移和定位
一致性哈希
通过将所有的存储节点放在首尾相连的hash环上,计算key时,把值放到环上面的一个节点做存储,如果需要做扩缩容时,只会影响到相邻节点的key重新设置。但这也同时会带来可能不同数据在扩缩容后,在不同节点上的分布是不均匀
redis为什么那么快
- 完全基于内存操作
- 优化过数据结构,涉及一些数据压缩、跳表等数据结构
- 使用单线程,无上下文切换成本
- 基于非阻塞的多路IO复用
注: 在6.0中的多线程主要是做数据协议读取上面的解析,而执行命令依旧是单线程的
IO多路复用
redis在单线程中可以监听多个Socket的请求,在任意一个socket可读、可写时,redis去读取客户端请求,并在内存中进行操作,并把数据返回给对应的socket
非CPU密集性
在key-value以及其他加持下,redis的瓶颈更多是网络、内存带宽,而不是cpu密集型,所以在单节点无法支撑时,应该考虑组成redis集群,通过多节点来解决问题

