Spring Cloud
微服务架构领域核心
组件配置
Eureka、Ribbon、Feign、Hystrix、Zuul 等组件
业务场景设计
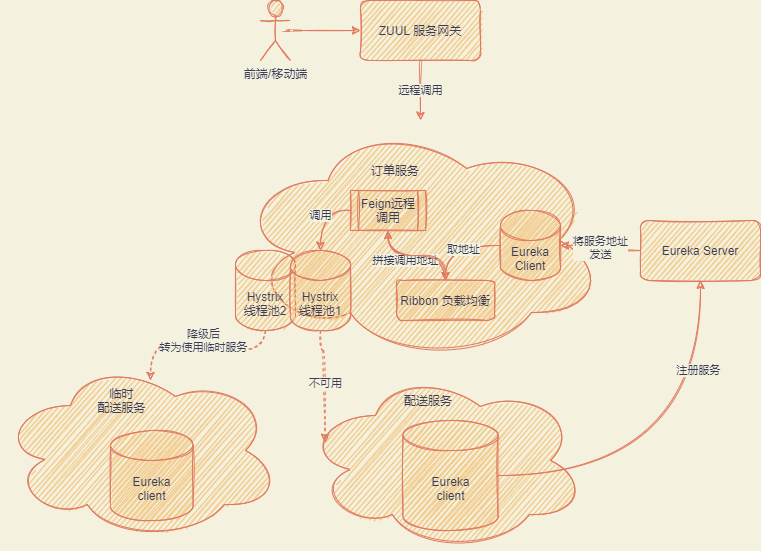
比如说这样子的业务场景,外卖 APP,用户下单喜欢的菜,支付订单,扣减菜的库存,通知外卖小哥以及商家出货。
像以上的业务场景,按微服务切分就可以有订单服务模块、库存模块、商家模块、快送模块
其中由订单模块统筹大局进行管理
- 操作订单的支付
- 管控库存的扣减
- 通知商家出货
- 通知快送模块进行配送
组件间的协作
微服务间怎么用这些组件进行串联
Erureka
首先要调用微服务,就需要知道对应的地址,服务信息等,这个就是由 Eureka 服务注册中心管理
Eureka service-registration-and-discovery
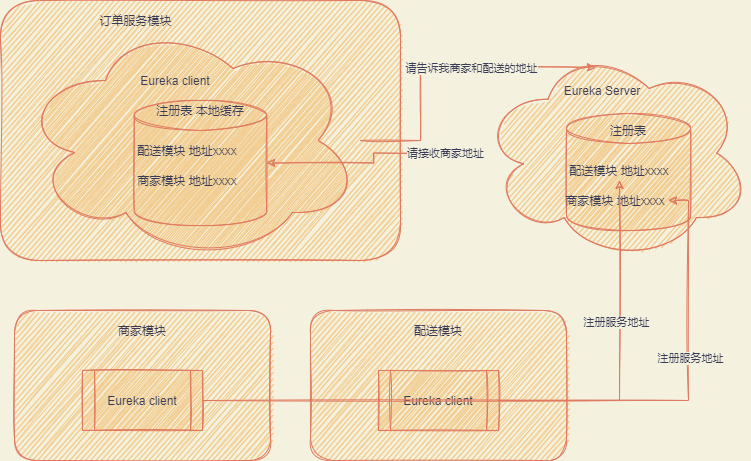
Eureka 连环炮
- EurekaServer 要部署多少台机器
- 系统服务对 EurekaServer 实际访问流量以及 TPS
- Eureka 怎么存储服务的地址信息,数据结构是怎么样的
- 服务拉取注册表的方式以及频率
- Eureka 从技术层面上如何抗住日千万级别的访问流量
Eureka 拉取服务以及心跳机制
关于拉取频率和心跳机制可以参考官方文档
Being an instance also involves a periodic heartbeat to the registry (through the client’s serviceUrl) with a default duration of 30 seconds. A service is not available for discovery by clients until the instance, the server, and the client all have the same metadata in their local cache (so it could take 3 heartbeats)
翻译过来,就是 Eureka client 心跳机制为 30 秒一次,通知 Eureka Server 正常。对于每一个 Eureka Client 而言,去 Eureka Server 拉取最新的服务也是 30 秒一次,看看注册表有没有更新的内容。
PS: 服务只要在实例、server、client 的本地缓存都有同样数据时,才能对外发布使用,最长的话可能需要花费三次心跳时间。
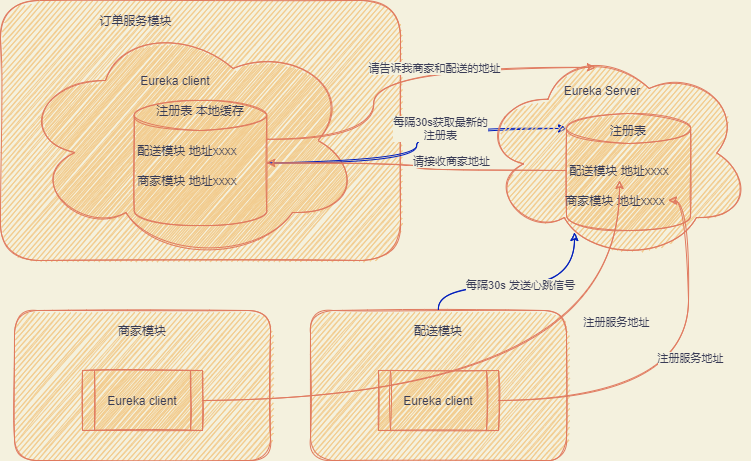
Eureka 的访问量计算
比如说有 50 个服务、每个服务有 3 个机器,那么就是有 503=150 个服务实例。每个服务实例正常是每分钟发送两次心跳信号,拉取两次注册表,当它请求 4 次,4150=600 次每分钟。
换算成秒也才 600/60s=10TPS,这方面的压力不大,假如部署的服务更多,那大致在 TPS1、200 左右,那么 Eureka 是怎么保证高性能的呢?
Eureka 的数据结构
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
// 内存使用ConcurrentHashMap进行存储相关服务注册信息
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap();
}
- ConcurrentHashMap
key服务名字比如说配送服务Map<String,Lease<InstanceInfo>>服务对应的服务实例,比如说配送服务 1,配送服务 2String对应着服务实例的 idLease<InstanceInfo>Lease 记录了服务上一次心跳,Purpose is to avoid accumulation of instances in AbstractInstanceRegistry as result of ungraceful shutdowns that is not uncommon in AWS environments.InstanceInfo也就是每个实例的具体信息,比如说 ip 地址等信息
讲完了数据结构,那么技术上如何保证这份内存实例可以高并发读写呢?答案是多级缓存的机制
Eureka 多级缓存
public class ResponseCacheImpl implements ResponseCache {
private final ConcurrentMap<Key, Value> readOnlyCacheMap = new ConcurrentHashMap<Key, Value>();
private final LoadingCache<Key, Value> readWriteCacheMap;
private final AbstractInstanceRegistry registry;
缓存机制
- 先从 ReadOnlyCacheMap 读取配置信息
- 如果没有再从 readWriteCacheMap 里面读取注册表
- 最后读取实际的注册表即 registry 中的内容
如果有注册等行为发生时
- 先登记到 registry 中,然后调用
invalidateCache过期掉readWriteCacheMap - 此时 client 还可以读取 readOnlyCacheMap 中的内容
- 后台也有起
TimeTask任务定期将ReadWriteCacheMap中内容同步到ReadOnlyCacheMap,即此时 ReadOnlyCacheMap 也会清空 - 如果有 client 拉取服务,从 registry 获取最新数据,再填充缓存
- 先登记到 registry 中,然后调用
通过这个机制,可以有效分担读写流量,保证性能以及高吞吐量
总流程图如下
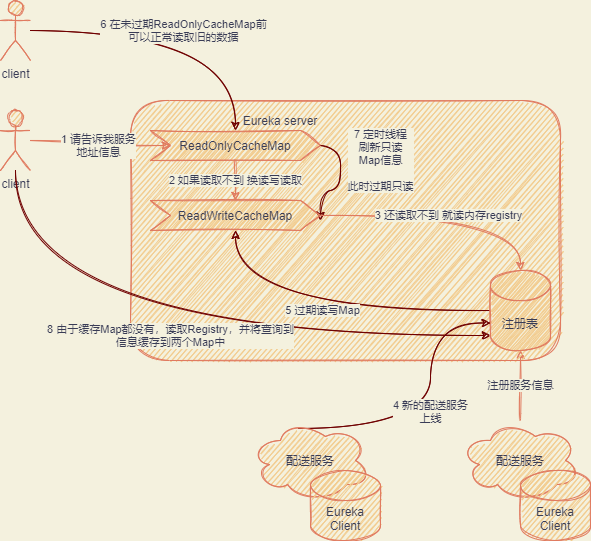
读写锁优化机制
此处很多官方文档都写错了的囧 o(╯□╰)o,
AbstractInstanceRegistry在代码实现时是读的操作上写锁,写的操作上读锁,与网上一堆文章是相反的,下面记录下 Eureka 为什么要怎么做。
快速简要:读写锁将读、写锁分开,实现读读不互斥,读写互斥,写写互斥,这样子可以保证并发读的场景,适用于读多写少的场景,比如说像 Eureka 这种读明显大于写的场景。
| 方法名 | 是读逻辑还是写逻辑 | 读锁 | 写锁 | 不适用锁 |
|---|---|---|---|---|
| register | 写 | √ | ||
| internalCancel | 写 | √ | ||
| statusUpdate | 写 | √ | ||
| deleteStatusOverride | 写 | √ | ||
| getApplicationDeltas | 读 | √ | ||
| getApplicationDeltasFromMultipleRegions | 读 | √ | ||
| renew | 写 | √ | ||
| evict | 写 | √ | ||
| getApplicationsFromMultipleRegions | 读 | √ |
为什么写操作上读锁与读操作上写锁相反呢?这是由于 Eureka 应用集合一致性哈希码导致的,我们先看到写操作上读锁的两个方法getApplicationDeltas以及getApplicationDeltasFromMultipleRegions
// 上锁主要是为了recentlyChangedQueue 以及registry的共享变量的应用实例状态一致,保证返回的赠礼应用实例集合的状态是准确的
try {
// !!!!! 写锁上锁 !!!!!!!!!!
write.lock();
Iterator<RecentlyChangedItem> iter = this.recentlyChangedQueue.iterator();
logger.debug("The number of elements in the delta queue is :{}", this.recentlyChangedQueue.size());
// 取recentlyChangedQueue放到apps,最后会做一个hashcode的计算
while (iter.hasNext()) {
Lease<InstanceInfo> lease = iter.next().getLeaseInfo();
InstanceInfo instanceInfo = lease.getHolder();
logger.debug("The instance id {} is found with status {} and actiontype {}",
instanceInfo.getId(), instanceInfo.getStatus().name(), instanceInfo.getActionType().name());
Application app = applicationInstancesMap.get(instanceInfo.getAppName());
if (app == null) {
app = new Application(instanceInfo.getAppName());
applicationInstancesMap.put(instanceInfo.getAppName(), app);
apps.addApplication(app);
}
app.addInstance(decorateInstanceInfo(lease));
}
if (includeRemoteRegion) {
for (String remoteRegion : remoteRegions) {
RemoteRegionRegistry remoteRegistry = regionNameVSRemoteRegistry.get(remoteRegion);
if (null != remoteRegistry) {
Applications remoteAppsDelta = remoteRegistry.getApplicationDeltas();
if (null != remoteAppsDelta) {
for (Application application : remoteAppsDelta.getRegisteredApplications()) {
if (shouldFetchFromRemoteRegistry(application.getName(), remoteRegion)) {
Application appInstanceTillNow =
apps.getRegisteredApplications(application.getName());
if (appInstanceTillNow == null) {
appInstanceTillNow = new Application(application.getName());
apps.addApplication(appInstanceTillNow);
}
for (InstanceInfo instanceInfo : application.getInstances()) {
appInstanceTillNow.addInstance(instanceInfo);
}
}
}
}
}
}
}
// !!! 获取所有的实例,然后再计算应用hashCode,在下面这个方法中我们可以看到对registry的调用,写锁也就是主要为了锁最近改变列表以及这个registry !!!!
Applications allApps = getApplicationsFromMultipleRegions(remoteRegions);
apps.setAppsHashCode(allApps.getReconcileHashCode());
return apps;
} finally {
write.unlock();
}
public Applications getApplicationsFromMultipleRegions(String[] remoteRegions) {
boolean includeRemoteRegion = null != remoteRegions && remoteRegions.length != 0;
logger.debug("Fetching applications registry with remote regions: {}, Regions argument {}",
includeRemoteRegion, remoteRegions);
if (includeRemoteRegion) {
GET_ALL_WITH_REMOTE_REGIONS_CACHE_MISS.increment();
} else {
GET_ALL_CACHE_MISS.increment();
}
Applications apps = new Applications();
apps.setVersion(1L);
// !!!!!!!对registry的调用查询 !!!!!!
for (Entry<String, Map<String, Lease<InstanceInfo>>> entry : registry.entrySet()) {
Application app = null;
if (entry.getValue() != null) {
for (Entry<String, Lease<InstanceInfo>> stringLeaseEntry : entry.getValue().entrySet()) {
Lease<InstanceInfo> lease = stringLeaseEntry.getValue();
if (app == null) {
app = new Application(lease.getHolder().getAppName());
}
app.addInstance(decorateInstanceInfo(lease));
}
}
if (app != null) {
apps.addApplication(app);
}
}
if (includeRemoteRegion) {
for (String remoteRegion : remoteRegions) {
RemoteRegionRegistry remoteRegistry = regionNameVSRemoteRegistry.get(remoteRegion);
if (null != remoteRegistry) {
Applications remoteApps = remoteRegistry.getApplications();
for (Application application : remoteApps.getRegisteredApplications()) {
if (shouldFetchFromRemoteRegistry(application.getName(), remoteRegion)) {
logger.info("Application {} fetched from the remote region {}",
application.getName(), remoteRegion);
Application appInstanceTillNow = apps.getRegisteredApplications(application.getName());
if (appInstanceTillNow == null) {
appInstanceTillNow = new Application(application.getName());
apps.addApplication(appInstanceTillNow);
}
for (InstanceInfo instanceInfo : application.getInstances()) {
appInstanceTillNow.addInstance(instanceInfo);
}
} else {
logger.debug("Application {} not fetched from the remote region {} as there exists a "
+ "whitelist and this app is not in the whitelist.",
application.getName(), remoteRegion);
}
}
} else {
logger.warn("No remote registry available for the remote region {}", remoteRegion);
}
}
}
// 计算哈希code
apps.setAppsHashCode(apps.getReconcileHashCode());
return apps;
}
以及 hashCode 计算代码以及方程式
$$ appsHashCode =eachInstance( status+count) $$
比如说 4 个 UP、0 个 DOWN 就类似
$$ appsHashCode= UP4 + DOWN0 $$
/**
* Gets the hash code for this <em>applications</em> instance. Used for
* comparison of instances between eureka server and eureka client.
*
* @return the internal hash code representation indicating the information
* about the instances.
*/
@JsonIgnore
public String getReconcileHashCode() {
TreeMap<String, AtomicInteger> instanceCountMap = new TreeMap<String, AtomicInteger>();
populateInstanceCountMap(instanceCountMap);
return getReconcileHashCode(instanceCountMap);
}
可能有点疑惑,读写锁与这个一致性哈希计算到底有什么关系。
1️⃣ 要保证这个哈希 code 是一致性的,也就是获取时不允许有写操作的发生。
2️⃣ 不允许有写操作,那我们上读锁也可以,这段时间不会有写操作,同时也可以让其他人读取。
3️⃣ 但问题来了,在本例中,registry 以及 recentlyChangedQueue 的写方法更多,读取相对更少,可以参考下面两张截图
4️⃣ 对于 Eureka 这种读多的场景,肯定是要优先保证读的性能,那么我们就肯定是得让读操作不受影响。
5️⃣ 写操作多,假如我们给写操作上写锁,那么写期间,就没办法做读了,阻塞住
6️⃣ 但如果我们给写操作上的是读锁,随便它怎么改 registry、recentlyChangedQueue,也不会影响到别人。
此外,假如我们真的需要获取应用增量实例信息,我们这时是尝试上写锁,会与读锁冲突,如果拿不到,那我们就等待读锁释放。等拿到写锁后,我这个获取实例的动作是互斥的,能保证数据一致性的。
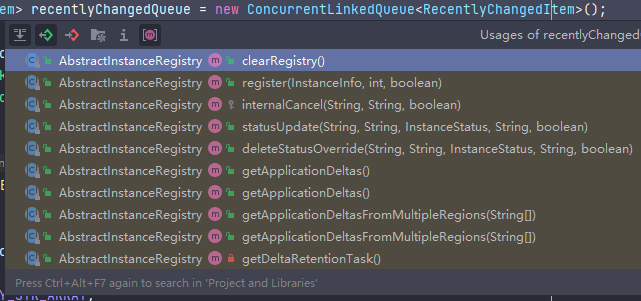
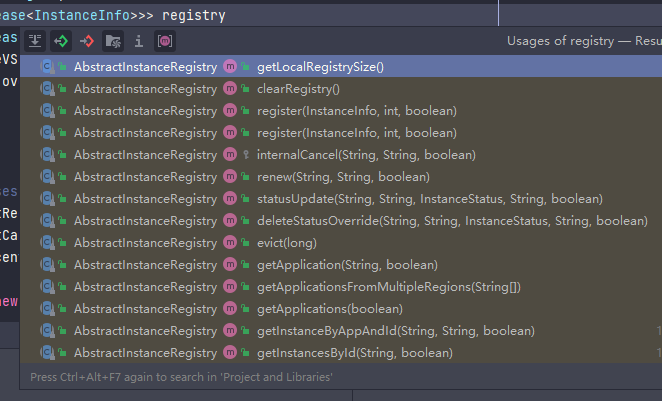
Hystrix
微服务系统中经常会面临一种问题,当某某服务宕机时,怎么保证整个系统的稳定性。比如说配送服务宕机了,大量的请求涌入了进来,由于配送服务不响应,导致订单全部 hang 住,继而拖垮整个应用。
这种问题又称为服务雪崩问题
为了避免这种问题,引入了 Hystrix 的组件进行服务熔断、隔离、降级的情况。HyStrix 的核心原理在于设置很多的小线程池,通过对小线程池的管控实现熔断、降级等
举个例子:比如说外卖配送的逆风服务宕机了,但其他的外卖小哥还可以正常服务啊,完全可以把逆风服务这块的功能熔断,优先尝试其他服务,这种也可以成为降级。如果我们彻底不要配送服务,就称为熔断。
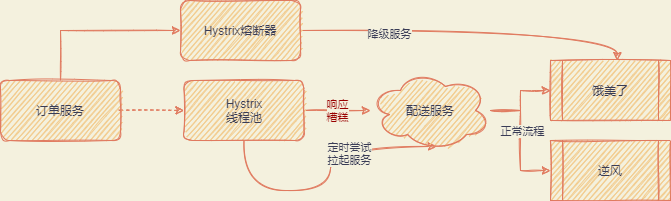
Zuul
API 服务网关,提供服务给前端、移动端等系统,便于做统一的认证、安全、限流等情况,同时前端也不需要了解微服务的部署情况以及相应的信息
Feign
在 Eureka 中我们知道了服务对应的地址信息,我们还需要 Feign 来帮我们实现轻松的服务调用,建立服务连接、发起请求、获取响应、解析响应等等。
Feign 的核心原理在于用动态代理进行调用
- 对使用了
@FeignClient注解的接口创建动态代理 - 调用接口的动态代理
- 根据接口上的
@RequestMapping、@FeignClient、@pathVariable等注解构造注解地址 - 根据产生的地址进行远程服务调用
Ribbon
上面我们知道了 Feign 要组装远程服务地址,但如果服务有多个,那要怎么取舍,怎么做负载均衡呢,这时就需要 Ribbon 来做服务的负载均衡,由它来选择最终要调用的服务

SpringCloud 组件架构