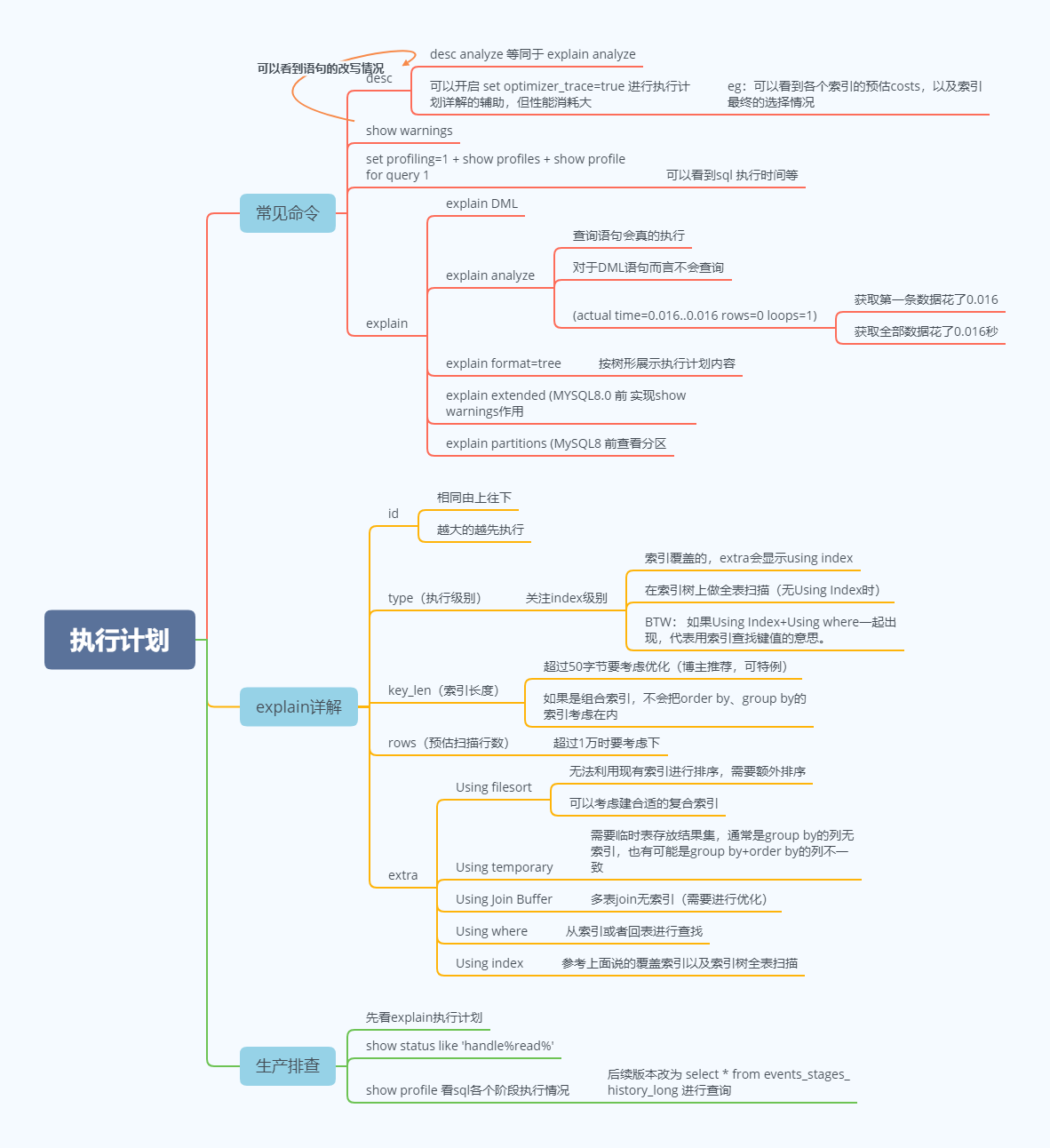
执行计划
DRDS 执行计划
- DRDS 语法
explain select ....对于 drds 时是展示分库信息explain execute select ....对于 drds 是展示执行计划- drds 只能看到 select 的执行计划,对于其他语句,将相关内容改为 select 进行解读就好
- MySQL 语法
explain sql···sql 执行计划
-- DRDS的执行计划
explain select id from test_no_index;
-- 查看执行计划
+----+-------------+---------------+------------+-------+---------------+-----+---------+--------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------+------------+-------+---------------+-----+---------+--------+------+----------+-------------+
| 1 | SIMPLE | test_no_index | <null> | index | <null> | id | 4 | <null> | 1 | 100.0 | Using index |
+----+-------------+---------------+------------+-------+---------------+-----+---------+--------+------+----------+-------------+
explain select id from test_index;
+----+-------------+------------+------------+-------+---------------+---------+---------+--------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+--------+--------+----------+-------------+
| 1 | SIMPLE | test_index | <null> | index | <null> | PRIMARY | 4 | <null> | 498385 | 100.0 | Using index |
+----+-------------+------------+------------+-------+---------------+---------+---------+--------+--------+----------+-------------+
执行计划解读
| 字段 | 作用 | 关注点 |
|---|---|---|
| id | 执行顺序,id 值越大,越先执行,null 时表结果集,用于 union 等查询语句 | |
| select_type | sql 的查询类型(无子查询、from 中查询···) | 关注不同部分的执行计划 |
| table | 表名称 | 对于 drds 这类中间件来说,可能为 rds 分库或者 drds 层名称 |
| partitions | 分区(创建表时指定的分表列信息) | 关注 sql 对于分库的查询 |
| type | 怎么查的(全表、索引、range、子查询中用 ref、const(主键索引 or 唯一索引)、full_text 等 | 关注使用到的索引是什么类型的,能不能优化使用的索引类型。 |
| possible_keys | 可能用到的索引 | |
| key | 使用到的索引,是上者的子集合 | 此处关注索引类型 |
| key_len | 索引长度 | 关注索引长度 len=charType+length+1(允许 null)+2(变长列) |
| ref | 表示上述表的连接匹配条件 | 若用等值等数查询,此处为 const。如果为连接查询,被驱动表的执行计划显示驱动表的关联字段,若为表达式 or 函数,则此处为 func |
| rows | 扫描行数 | 通常情况下,rows 越小,效率越高 |
| filtered | 结果集占查询数据量的比 | |
| extra | 额外信息(using index 使用覆盖索引)(using where 使用 where 子句过滤结果集) |
对于上面每个字段的详细解读
-- 建表语句
CREATE TABLE `test_index` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` varchar(20) DEFAULT NULL,
`b` tinyint(3) DEFAULT NULL,
`c` varchar(4) DEFAULT NULL,
`d` tinyint(4) DEFAULT NULL,
`e` varchar(5) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_id_b` (`id`,`b`)
) ENGINE=InnoDB AUTO_INCREMENT=500001 DEFAULT CHARSET=utf8
select_type
- SIMPLE 简单的 select 语句(不使用 union 或者子查询)
explain select * from test_index;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE test_index NULL ALL NULL NULL NULL NULL 498375 100 NULL - PRIMARY 最外层查询
- SUBQUERY 第一个子查询语句
explain select * from test_index where id = (select id from test_index limit 1);id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 PRIMARY test_index NULL const PRIMARY,idx_id_b PRIMARY 4 const 1 100 NULL 2 SUBQUERY test_index NULL index NULL idx_id_b 6 NULL 498375 100 Using index - UNION
- union result 结果
explain select id from test_index union select id from student;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 PRIMARY test_index NULL index NULL idx_id_b 6 NULL 498375 100 Using index 2 UNION student NULL index NULL idx_a 9 NULL 1 100 Using index NULL UNION RESULT <union1,2> NULL ALL NULL NULL NULL NULL NULL NULL Using temporary - DEPENDENT UNION union 语句,但是执行结果依赖外部查询
- DEPENDENT SUBQUERY 执行结果依然外面的子查询
explain select id from test_index begin where id in ( select id from test_index union select id from student where a=begin.a);id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 PRIMARY begin NULL index NULL idx_a 63 NULL 498375 100 Using where; Using index 2 DEPENDENT SUBQUERY test_index NULL eq_ref PRIMARY,idx_id_b PRIMARY 4 func 1 100 Using index 3 DEPENDENT UNION student NULL eq_ref PRIMARY,idx_a PRIMARY 4 func 1 100 Using where NULL UNION RESULT <union2,3> NULL ALL NULL NULL NULL NULL NULL NULL Using temporary - DERIVED 派生表,本质上就是
select ** from (xxx) T;实际上是一种特殊的 subQuery,位于 sql 语句中的 from 子句中,可以看做是一张表,5.7 之前处理为对 Derived table 进行 Materialize,生成临时表保存结果,然后利用临时表协助完成其他父查询操作。
5.7 允许将符合条件的 Derived table 中的字表与父查询表合并直接 join
table 表名称
type join type
- system 表只有一行(系统表也是),这也是一种典型的 const join 方式
- const 查询条件中的表只有一行匹配的,查询最快因为只读取一次
-- 根据主键ID查询只有一行 explain select * from test_index where id = 1;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE test_index NULL const PRIMARY,idx_id_b PRIMARY 4 const 1 100 NULL - eq_ref 从查询表中只取出一条进行联结,可能是最好的 join 联结方式,使用的索引是主键、非空的唯一索引。(然后 ref 列中为关联的字段)
-- 使用主键id进行关联 explain select * from test_index inner join student s on test_index.id =s.id;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE s NULL ALL PRIMARY NULL NULL NULL 1 100 NULL 1 SIMPLE test_index NULL eq_ref PRIMARY,idx_id_b PRIMARY 4 learn.s.id 1 100 NULL - ref 所有匹配条件的索引值用来进行联结,索引使用的是二级索引,如果查询只是匹配了一小部分行,这是一种好的查询方式。(然后 ref 列中为关联的字段)
explain select * from test_index inner join student s on test_index.a =s.a;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE s NULL ALL idx_a NULL NULL NULL 1 100 Using where 1 SIMPLE test_index NULL ref idx_a idx_a 63 learn.s.a 1 100 Using index condition - fulltext 使用全文索引
5.6 及以后引入全文索引,针对 char、varchar、text 及其系列建立全文索引
alter table test_index add fulltext key(a,c); select * from test_index where match(a,c) against('IyvECYO1uevFInzB5v4J dM77');id a b c d e 1 IyvECYO1uevFInzB5v4J 11 WKMw 100 BHwlX 2 EbQwRCmLzqeKQPtGTeiC 98 dM77 96 EZP1s 67640 1Q3wiMOAjD7tUVJJiaLa 24 dM77 96 DWDcX 111582 cvL8csv2wiKH7lbIQX3h 97 dM77 99 Mxeo7 471214 CVDhhp1JtYkyBd6I5ang 97 dM77 101 QRBfj id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE test_index NULL fulltext a a 0 const 1 100 Using where; Ft_hints: sorted - ref_or_null
附索引类型的执行效率:
all < index < range < ref < eq_ref < const < system
重点关注项
type 本次查询表链接类型
key 最终选择的索引
ken_len 本次查询用于结果过滤的索引实际长度(关注字段类型越短越好)
rows 扫描行数
extra 确认有无出现
Using filesort
MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause.
CREATE TABLE `test_index` ( `id` int(11) not null auto_increment, `a` varchar(20), `b` tinyint(3), `c` varchar(4), d tinyint, e varchar(5), primary key (id) ) ENGINE = InnoDB DEFAULT CHARSET = utf8; alter table test_index add index idx(b); alter table test_index add index idx_c(c); explain select * from test_index where b=3 order by c ;当查询的条件与 order by 条件不一致时,先根据索引查出来值,然后再根据另外的值进行排序,也就是
using filesort+----+-------------+------------+------------+------+---------------+-----+---------+-------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+-----+---------+-------+------+----------+---------------------------------------+ | 1 | SIMPLE | test_index | <null> | ref | idx | idx | 2 | const | 4506 | 100.0 | Using index condition; Using filesort | +----+-------------+------------+------------+------+---------------+-----+---------+-------+------+----------+---------------------------------------+解决方法:添加联合索引 idx_b_c(b,c)
alter table test_index add index idx_b_c(b,c); +----+-------------+------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | test_index | <null> | ref | idx,idx_b_c | idx_b_c | 2 | const | 4506 | 100.0 | Using index condition | +----+-------------+------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+Using temporary 需要创建一个临时表来存储结果,这通常发生在对没有索引的列进行 GROUP BY 时,或者
ORDER BY里的列不都在索引里Using index 覆盖索引
查询的字段都在索引树上可执行,并查询出来结果
Using where 通常是进行了全表引扫描后再用 WHERE 子句完成结果过滤
Impossible WHERE 对 Where 子句判断的结果总是 false 而不能选择任何数据,例如 where 1=0,无需过多关注
Select tables optimized away 使用某些聚合函数来访问存在索引的某个字段时,优化器会通过索引直接一次定位到所需要的数据行完成整个查询,例如 MIN()\MAX()
执行计划思维导图
实战场景
order by limit失效
-- 比如这样的一个sql
select id,name,desc from test_order_table where name=xx and desc=xx order by name desc limit 50;
然后索引建立的是
create idx_name_desc(name,desc)
但实际执行时却发现这是一个慢sql,看执行计划只能发现标记了filesort,但执行时间很缓慢,看数据时也没看到有什么好奇特的地方
If an index cannot be used to satisfy an ORDER BY clause, MySQL performs a filesort operation that reads table rows and sorts them. A filesort constitutes an extra sorting phase in query execution.
To obtain memory for filesort operations, the optimizer allocates a fixed amount of sort_buffer_size bytes up front. Individual sessions can change the session value of this variable as desired to avoid excessive memory use, or to allocate more memory as necessary.
A filesort operation uses temporary disk files as necessary if the result set is too large to fit in memory. Some types of queries are particularly suited to completely in-memory filesort operations. For example, the optimizer can use filesort to efficiently handle in memory, without temporary files, the ORDER BY operation for queries (and subqueries) of the following form:
大致就是优化器会通过sort_buffer做一定的优化,如果结果集太大了,也会考虑使用临时磁盘做一个存储,避免内存过多使用,而这也就是问题的所在
而像文中这个场景,我们可以通过开启优化器查询来观察语句执行详细情况
set optimizer_trace="enabled=on";
-- 执行sql
select * from information_schema.optimizer_trace;
-- 查看我们sql中关于filesort的使用情况,里面会列出内存使用情况,甚至说是文件使用情况
对于上面问题的解决是,尝试把你需要排序的数据集大小进行减少,我这里的场景是因为有一些用户的测试数据太大了,导致了慢sql,在实际场景中,如果你确实有用户有这么大的数据量,建议采取一些热点缓存,或者说把数据做一些分表,或者通过多次查询,比如先查出匹配的id,减少要sort的数据集大小,再用id手动进行回表查询

