前言:
现在用的是日志易的产品,通过traceId能够查出所有链路上的日志,用是会用了,但确实对这是怎么实现的,没有了解过。今天也算是补下这块的内容,避免一问三不知的情况
日志
通过日志,可以查询到一笔交易涉及到的所有关联系统,它们各自的交易耗时,又可以通过traceId【全局唯一ID】+parentId【父系统ID】or SPANID【各系统自ID】 查出相应日志,基于这种能做消息的收集、分析,日志告警等。
全链路日志
全链路的相关原理大都基于论文《Google Dapper》的描述,有兴趣的可以翻阅下
组成模块
以下模块按实际需求选择相应的模块替代即可
| 模块名 | 含义 |
|---|---|
| 全局traceId | 既然要做到查询每一笔交易的完整链路,那么它们的traceId就不肯定不能共用的,这一块就涉及到了如何高效生成全局ID的问题,这块可以参考雪花算法等实现方式 |
| SpanId | 作为基本工作单元,交易链路上的每个子环节,都生成自己的SpanId作为唯一标志 |
| parentId | 记录父节点,相当于链表的prev节点了 |
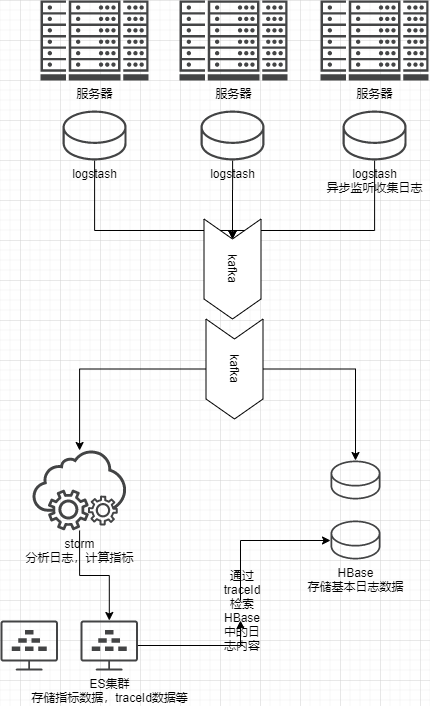
| 存储以及检索 | 日志的存储,以及快速检索方式(ES集群存储traceId节点,Hbase存储基础数据与traceID的关系) |
| 日志的收集以及清洗 | logstash插件等 |
| 消息队列的选用 | kafka |
调用链路
埋点
从服务端划分
- 服务端
- 客户端
- 服务端和客户端双向
从服务上
- rpc
- HTTP
实现上,在收到请求报文时,先通过拦截请求,在前置统一切面上做traceId的透传、spanId生成等内容,照常打印日志即可。
收集日志
- collector
- 按服务、应用级别分级收集日志
- 集群收集,经logstash处理后发往kafka处理
分析日志上
- traceId全局唯一,用traceId可查到一笔交易所有日志信息,通过parentId可以查到各系统具体的请求指标,可以做各系统交易链路耗时的分析,实现告警,服务降级、熔断等操作。收集出来的日志,按span排序后即为交易的timeline,便于排查问题

