面经学习
剖析自身
技术广度
到目前为止接触学习过哪些技术领域:MQ、Cache、NoSQL、大数据、高并发、高可用、微服务、分布式存储、分布式业务·····
如何落地技术、技术的业务场景
技术深度
- 技术的底层源码
- 架构设计思想
- 设计过业务领域的架构设计?
- 生产运维故障故障处理等
项目经验
- 做过具有挑战性的项目
- 高并发、高吞吐、海量数据?
项目管理
- 带过小组开发
- 设计开发
- 问题排查、把控代码质量等。
面试方法
- 小公司刷经验
- 查缺补漏知识
- 开始投大公司
- 查缺补漏
- 最后收尾挑选心仪的公司
面试准备
简历深度剖析
- 对于简历上的项目业务、技术场景要聊熟于心,能扛得住连环炮的询问
- 同时对于项目的拓展也要能接得住
公司的了解
- 尽可能了解公司业务背景、用户量等
- 关注公司的技术分享,了解对方的技术架构等
- 尽量往自己做过的项目上去做
算法练习
- 常见题目反复练习至能在白纸写出无 bug 的内容
- 栈、队列、链表、B+树、红黑树、二叉树等等
阿里
如何处理业务翻倍增长
首先是数据的落地存储,假如业务翻倍增长,首当其冲地是存储问题。
| 提问 | 答案 |
|---|---|
| 原先的单表是否足以存储庞大的数据量? | 不够,那考虑分库分表? |
| 分库分表要怎么分? | 500w 的基数,进行切分,如果实际业务情况仍超过预设的值,应该重新制定表的结构进行存储,考虑业务层把一定业务周期外的数据作为冷数据进行归档,只保留热数据,减小数据量的存储 |
| 分布式数据库选型有哪些? | 1. 客户端组件+单体数据库: Sharding-JDBC 应用层建立数据分片和路由规则,实现数据库的管理,对业务侵入较深。 2. 代理中间件+单体数据库: MyCat 以独立中间件形式存在管理数据规则,有些也会衍生出分布式事务的能力。 3. 单元化架构+单体数据库:垂直切分业务,每个支行自己管理自己的数据,当需要跨支行操作时,由业务层进行统筹管理 |
| 性能、吞吐量是否满足增长的业务需求? | 考虑数据异构、冷热分离的设计 |
| 数据异构、冷热分离的典型 | MySQL 分库分表+分布式 NoSQL 数据库+ElasticSearch 分布式搜索+Redis 缓存架构:先将热点数据存储到分布式 NoSQL、承载高并发读写,接着将冷数据归档到 MySQL、应对海量数据的搜索使用 ElasticSearch,对于秒杀场景可考虑 Redis |
说说使用技术的原理
对于项目里面用到的任何组件,都应了解其技术原理,性能 TPS,数据结构是怎么样的,怎么扩容,怎么存储,怎么规划。
说说系统开发中的难点
这里就应该说一些难点出来,比如说数据的迁移,迁移后数据比对校验,增量数据的追平,迁移切换中如何保证业务正常,迁移完成后的业务验证以及业务跟踪监控。
面试流程
连环炮发问
MQ
- 使用的消息中间件是什么
- 为什么要用消息中间件,遇到什么挑战了吗?
- 为什么选型是 RabbitMq
- 为什么不用 RocketMq 和 Kafka,依据是什么
- 如何保证消息中间件的高可用性,如果发生故障怎么处理?
- 如何保证消息投递一定不丢失
- 如何消息不会重复投递
- 是否有需要用到顺序消息的业务场景
- 如果不需要,为什么不需要?如果我现在有个场景需要,要怎么保证消费的顺序性
- 下游如果宕机,消息中间件堆积了海量数据,要怎么处理
- 如何处理积压的场景
- rabbitmq 的架构、原理、持久化逻辑
- rabbitmq 线上的 QPS 峰值,如何部署,机器配置情况
- kafka 怎么看的?架构、存储、分布式存储
- kafka 怎么实现高容错性?零拷贝技术?高吞吐量如何实现?
- kafka 源码阅读过吗?
- RocketMq 了解过吗?
- 如何设计一个分布式消息中间件?
NoSQL
- 有没有用到过 NoSQL
- 常用 NoSQL 的选型有什么
- NoSQL 可以解决什么问题?
Java 底层
- JVM 核心原理、内存、GC、FullGC 卡顿的排查、OOM 内存溢出排查
- volatie 原理、锁优化、AQS 源码·····
- IO、Netty 网络等等
项目经验询问
- 项目架构图
- 项目使用了什么技术,以及核心的业务流程思路是什么
- 继而是对技术的连环炮考验专业能力
Redis 业务
- 什么业务场景使用了 Redis
- 选用什么数据结构存储数据,过期时间如何评估?如果过期了,兜底方案是什么?如何回查?
- key 如何设计?
- 为什么要用 Redis 存储业务数据,选用其他数据库可以吗?
架构设计思维
- 如何设计电商秒杀系统
- 潮汐式业务情况如何应对
- 假如现在业务翻倍增长,系统上的技术架构要怎么调整?
高并发架构演进
架构一定是要适配业务场景下进行适度开发,比如像开发一个简单的业务,引入了一大堆设计模式,就会显得极为臃肿,或者说,只有 10TPS 的访问量,却加了 MQ、Redis、本地缓存、分布式数据库,不是说这样子设计不行,但是过度设计带来的是测试工作量变大,且拖长了工期,成本上划不来。
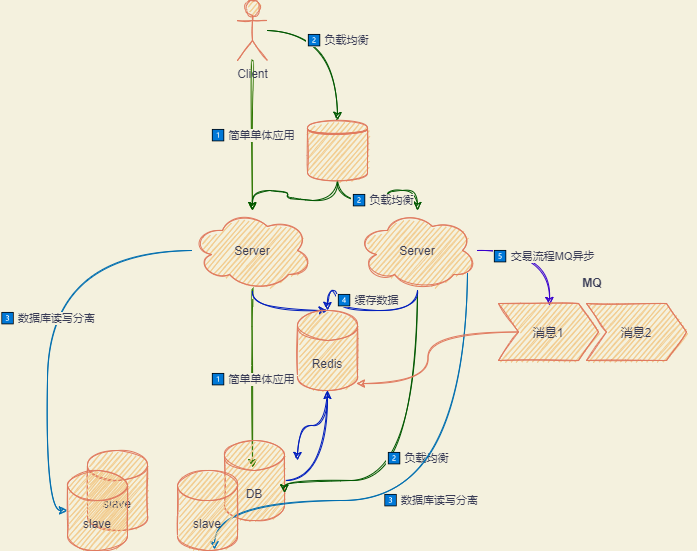
在这种架构下也无法支持业务的需求时,比如说 OLAP 的业务,需要实时知道各种报表指标的数据,这种就需要引入大数据模块进行支持
OLAP
| Question | Answer |
|---|---|
| 实时计算无法支撑时怎么办 | 引入离线计算模块,引入 Hadoop Hive/Spark 进行离线加工计算 |
| 本地存储数据量庞大怎么办 | 只保留短暂时间段内的数据,一周或者一天,其他数据转为冷备或者清除 |
| 实时计算选用什么架构 | 可以采用 flink、Druid 技术,通过流式计算,通过 State 状态记录计算每一次操作的结果,实时将流处理结果返回给客户、业务查看 |
| 离线计算能力不能支持时 | 可以考虑将全量计算转为增量计算,增量计算时看是否需要与全量数据进行混合计算,还是可以单独计算 |
| 分布式数据库支撑不住压力 | 主库只提供写,读全部从从库进行查询,避免 IO 过高 |
| 大量数据流入数据库 | MQ 异步入库,抗住流量,避免数据库承受大量的压力 |
| MQ 集群宕机怎么办 | 转为同步调用+限流机制 |
| 业务量还是太大,数据库无法支撑 | 拆分为多个业务的数据库分开存储 |
| Nginx 压力过大 | 通过 F5 等硬件进行负载均衡 |
| Mysql 压力依然过大 | 转为 NoSQL 数据库、搜索引擎进行解决,比如 HDFS 分布式文件系统解决文件存储;可以通过 HBase 和 Redis 等解决 Key-Value 的数据存储;通过 ES 集群实现搜索功能;多维分析上可以用 Kylin or Druid 查询。 |
| 服务拓展管理麻烦 | 引入容器化技术实现环境管理和服务管理,比如 k8s,Docker,Docker 打包镜像,用 k8s 进行动态分发和部署 |

