技术实现
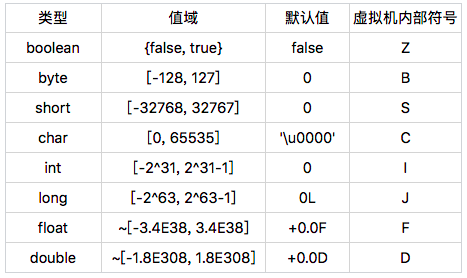
基本类型
- Jvm每次调用一个方法,创建一个栈帧
- 栈帧=局部变量区+字节码的操作数栈
- 实例方法的this指针以及方法接受的参数
- 局部变量区等同一个数组,可以用整数下标进行索引,除了long、double值需要两个数组单元存储外,其他基本类型以及引用仅占用一个数组单元
类加载过程
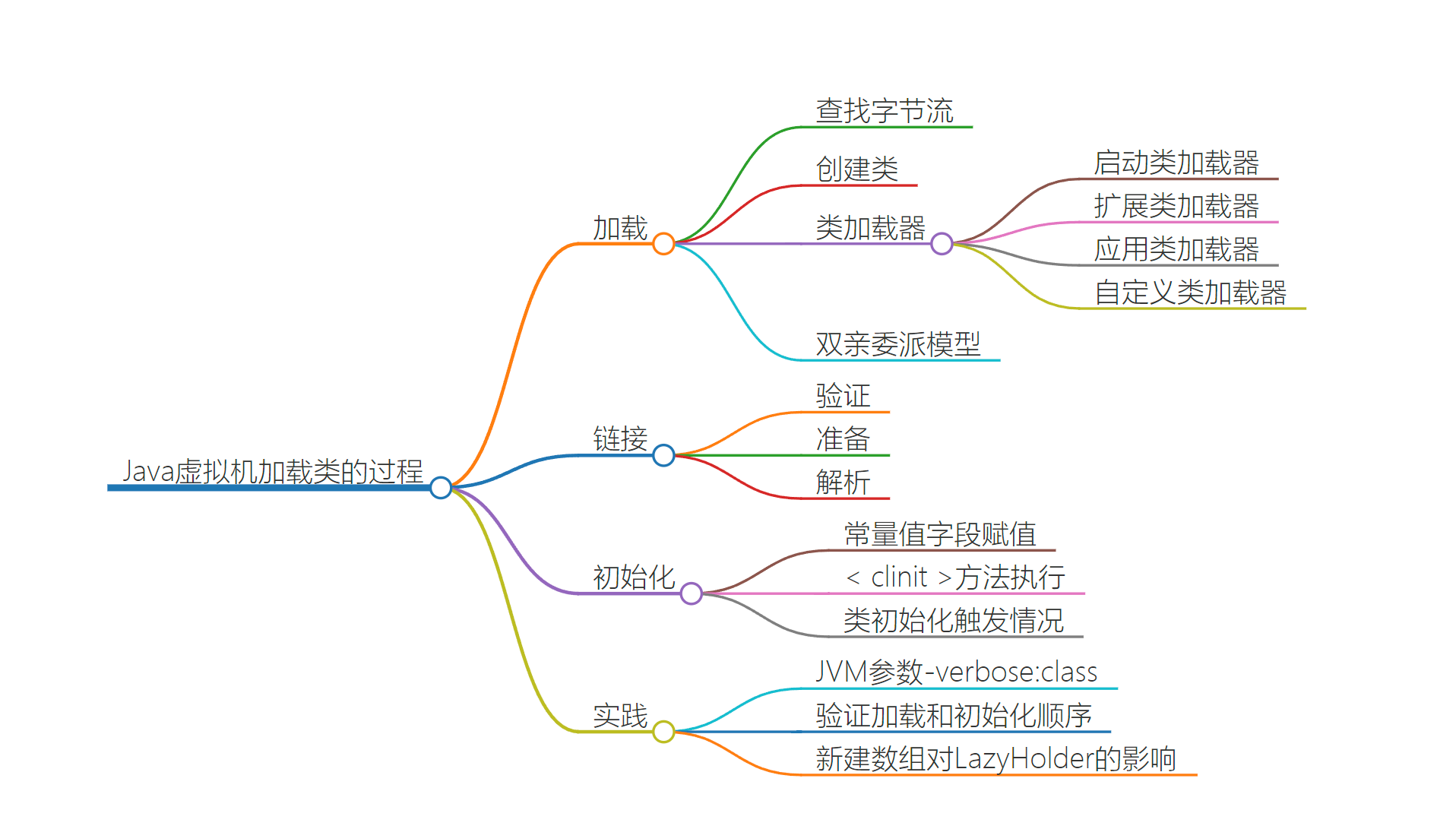
- 加载
- 查找字节流,创建类
- 双亲委派
- 优先给父类创建
- 链接
- 验证
- 校验约束条件
- 准备
- 分配内存等
- 解析
- 符号引用转为实际引用,变成实际要调用的方法
- 验证
- 初始化
- 静态字段赋值等
- 当虚拟机启动时,初始化用户指定的主类;
- 当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类;
- 当遇到调用静态方法的指令时,初始化该静态方法所在的类;
- 当遇到访问静态字段的指令时,初始化该静态字段所在的类;
- 子类的初始化会触发父类的初始化;
- 如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;使用反射 API 对某个类进行反射调用时,初始化这个类;
- 当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
JVM执行方法调用
- 识别方法
- 通过类名、方法名、方法描述符【描述符指参数类型以及返回类型】识别
- 调用方法的指令
- invokestatic调用静态方法
- invokespecial调用私有实例,构造器,super调用父类,接口的默认方法
- invokevirutal 非私有实例
- invokeinterface 调用接口方法
- invokedynamic 调用动态
- 调用指令的符号引用
- 因为编译时,不知道具体要调用谁,所以用符号引用进行替代
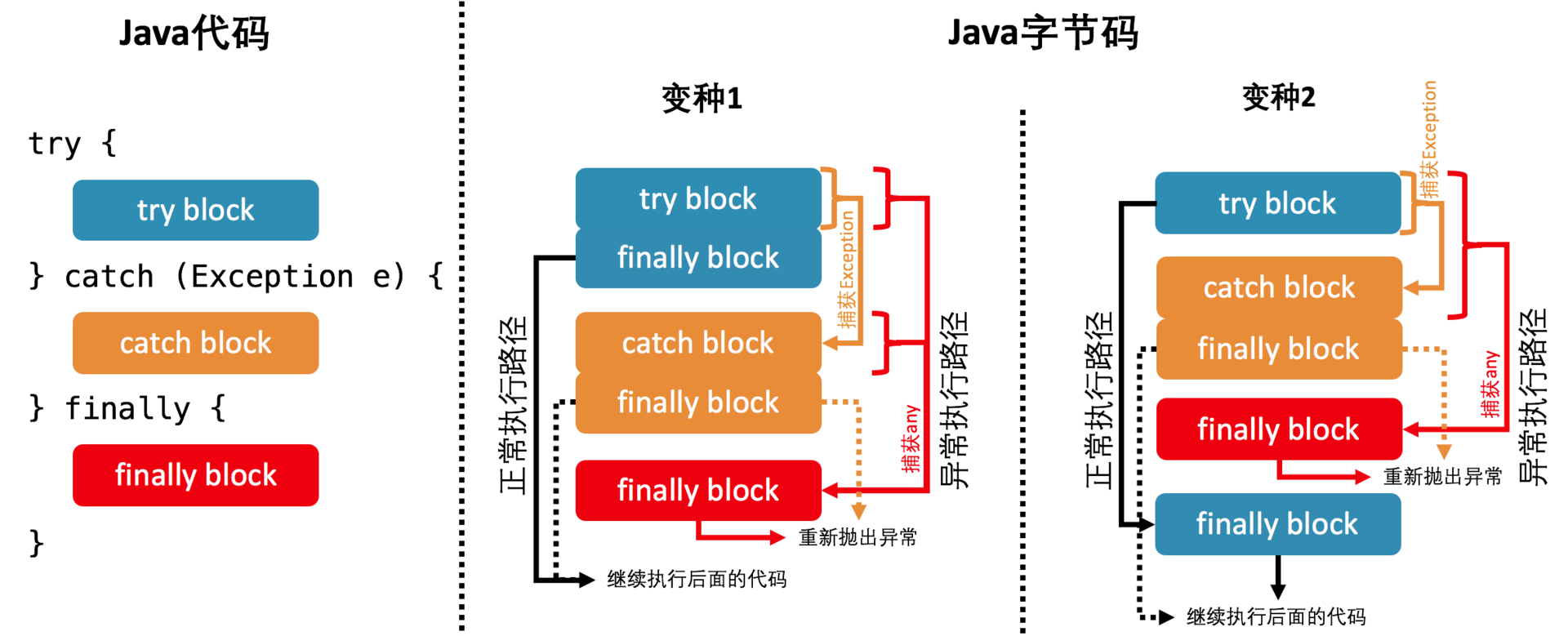
JVM处理异常
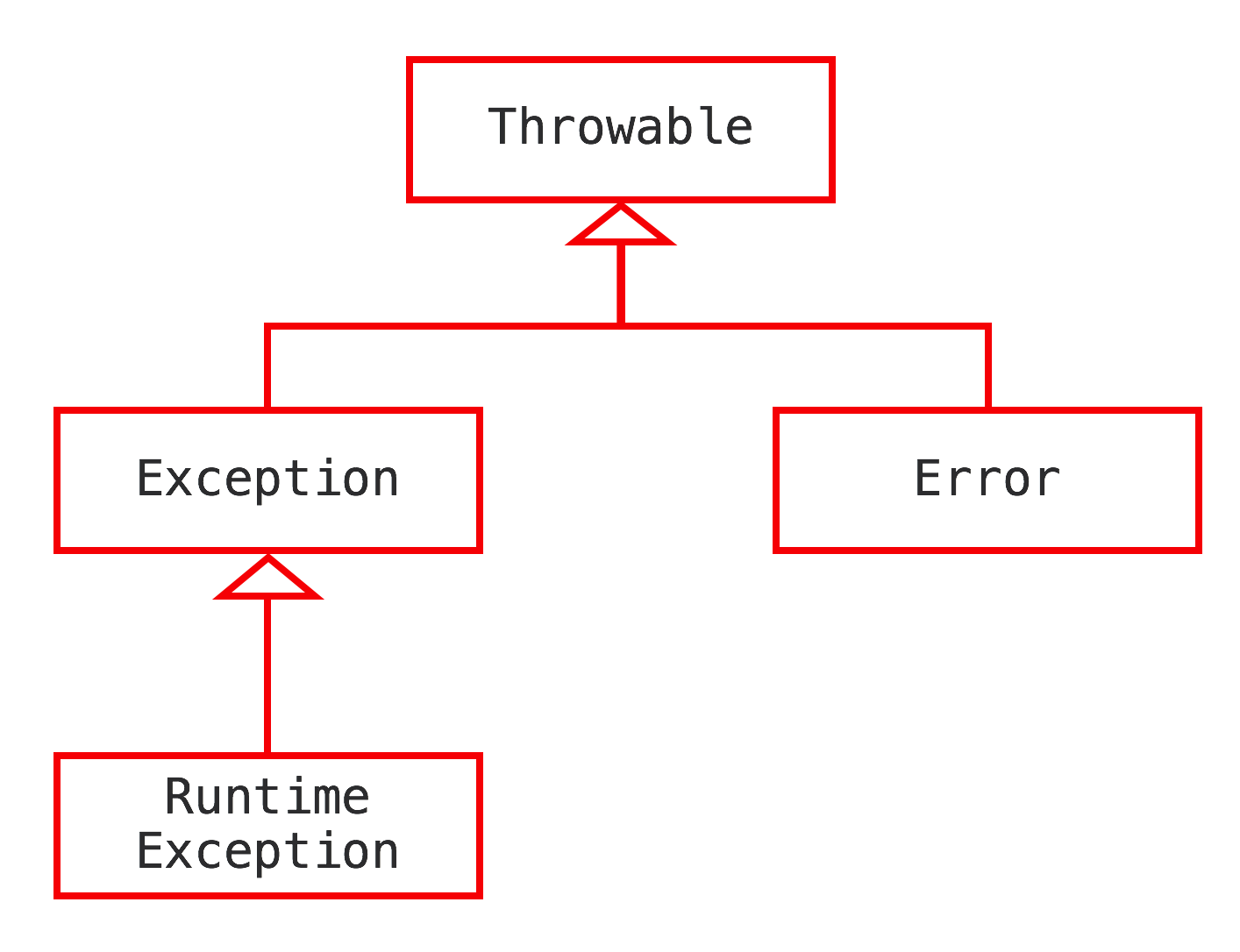
- 编译生成的字节码,每个方法都生成一个异常表,异常表每条类目代表一个异常处理器
- 由from指针、to指针、target指针以及捕获的异常类型组成
- from to 代表异常处理的监控范围
- target代表代表异常处理开始位置,代表catch块
- finally块的实现,复制finally的代码,到所有正常执行以及异常执行链路的出口中
反射实现
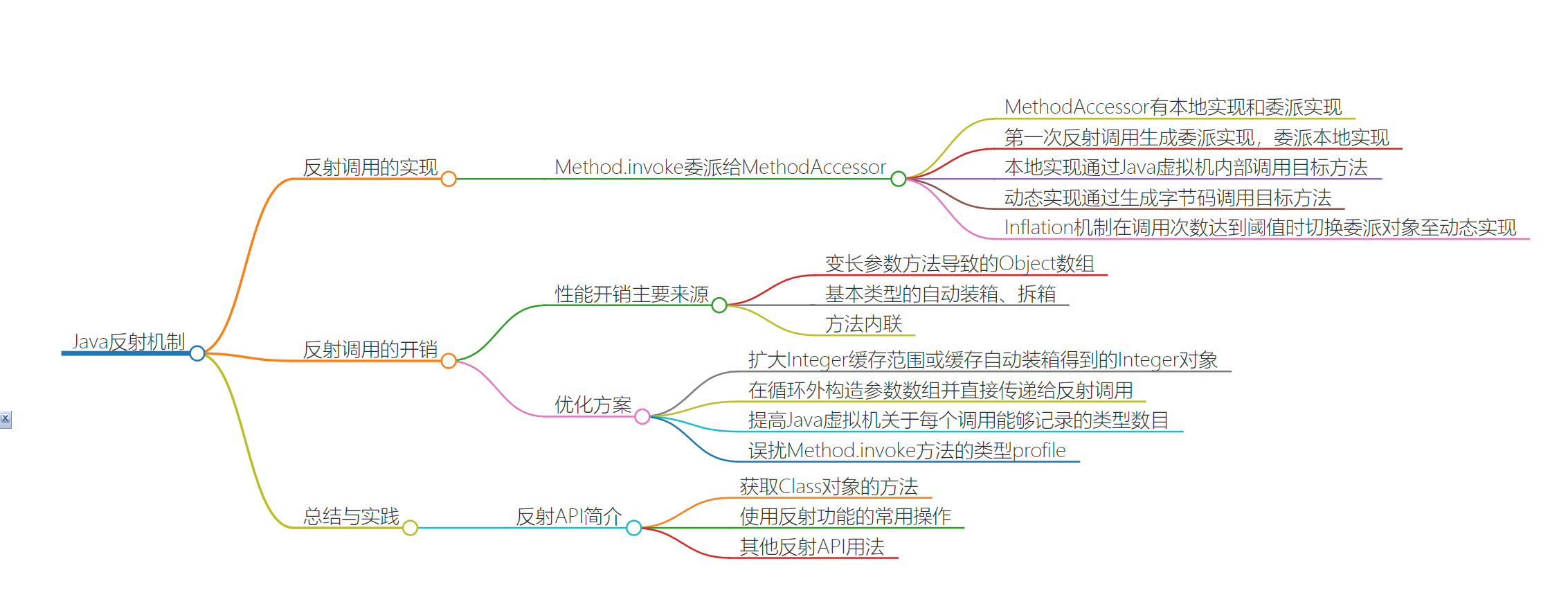
- 反射使用场景
- 比如IDE自动提示方法
- 动态类设置
public final class Method extends Executable {
...
public Object invoke(Object obj, Object... args) throws ... {
... // 权限检查
MethodAccessor ma = methodAccessor;
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
}
- 性能损耗点
- Method.invoke 变长参数方法
- Object数组不能存储基本类型,所以这里还涉及装箱
- 针对Integer的-128,127做了优化处理,自动返回缓存的Integer对象
invokeDynamic实现
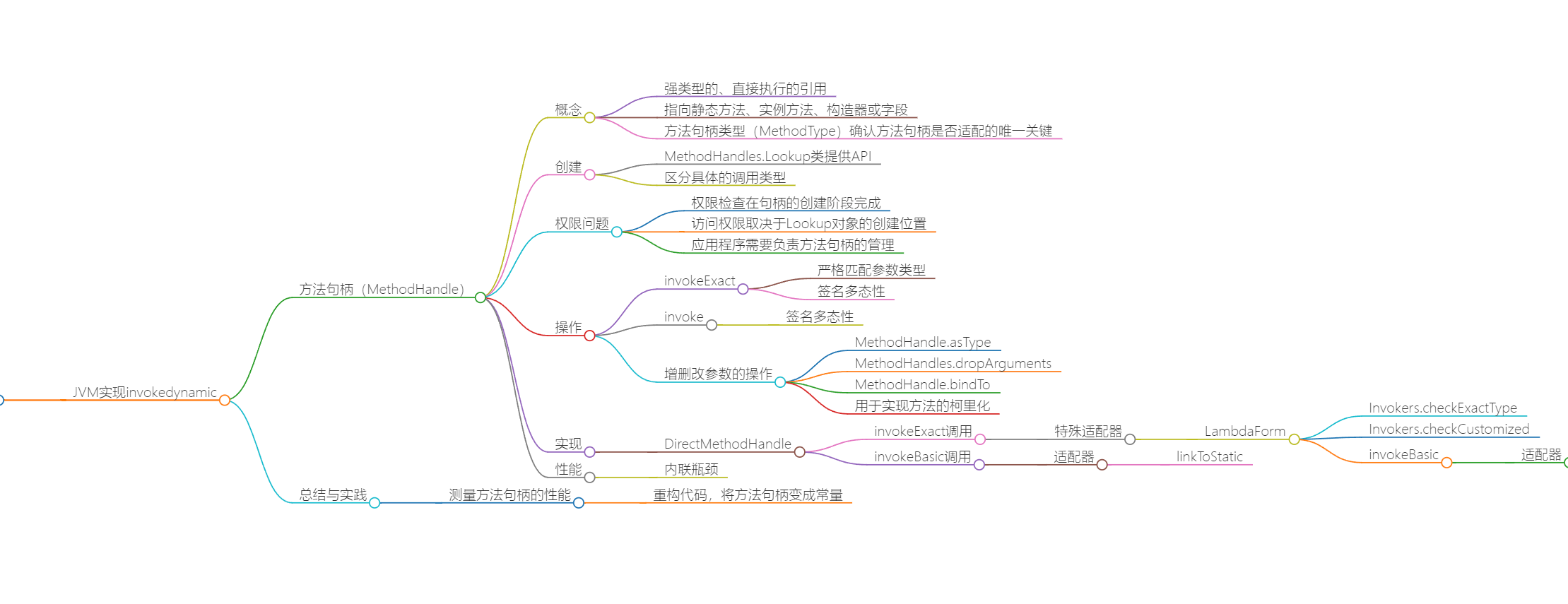
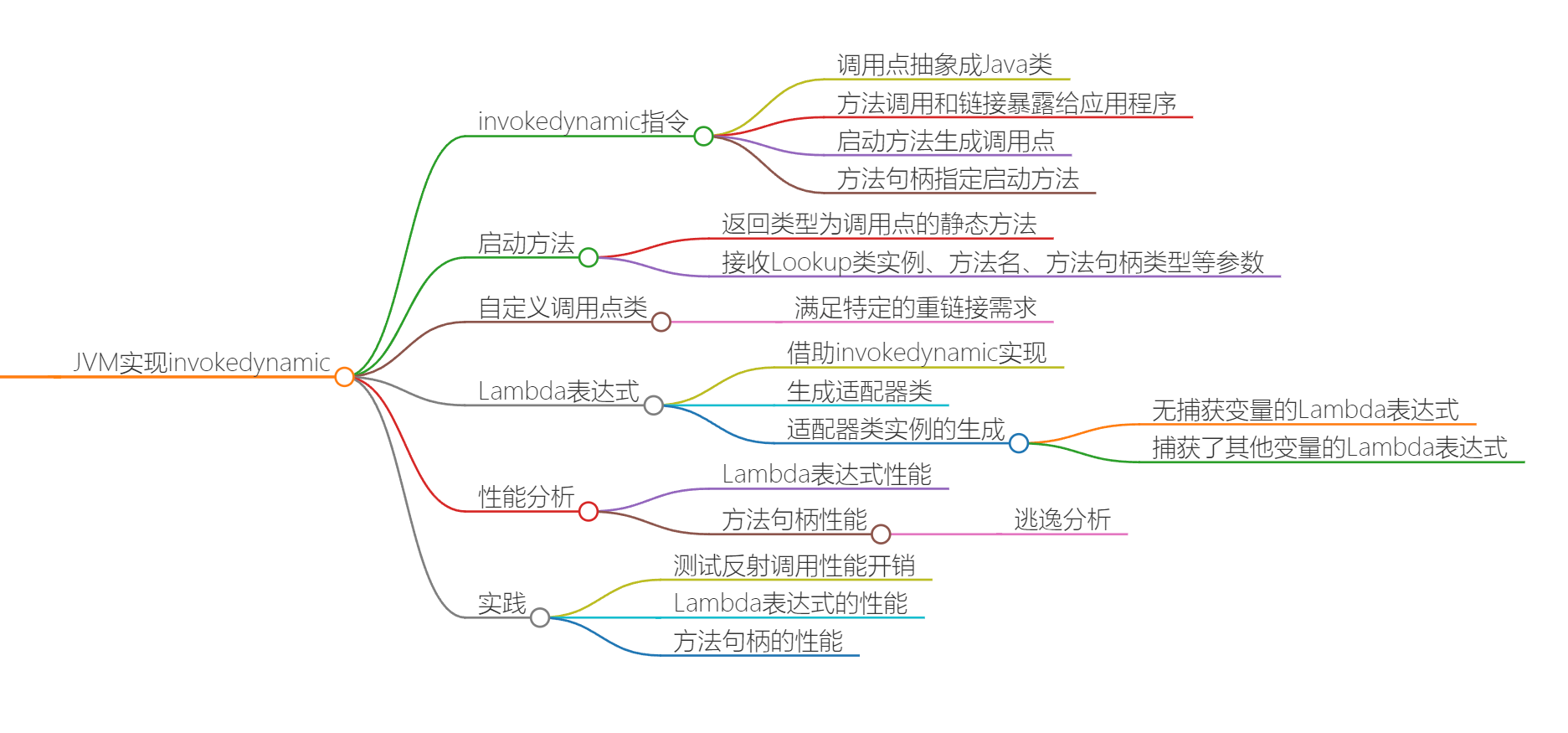
- 在第一次执行 invokedynamic 指令时,Java 虚拟机会调用该指令所对应的启动方法(BootStrap Method),来生成前面提到的调用点,并且将之绑定至该 invokedynamic 指令中。在之后的运行过程中,Java 虚拟机则会直接调用绑定的调用点所链接的方法句柄。
- lambda也是借助这个指令生成
- 生成函数式接口的适配器
- 函数式接口这里是指一个非default接口方法的接口,一般通过@FunctionInterface注解
Java对象内存分布
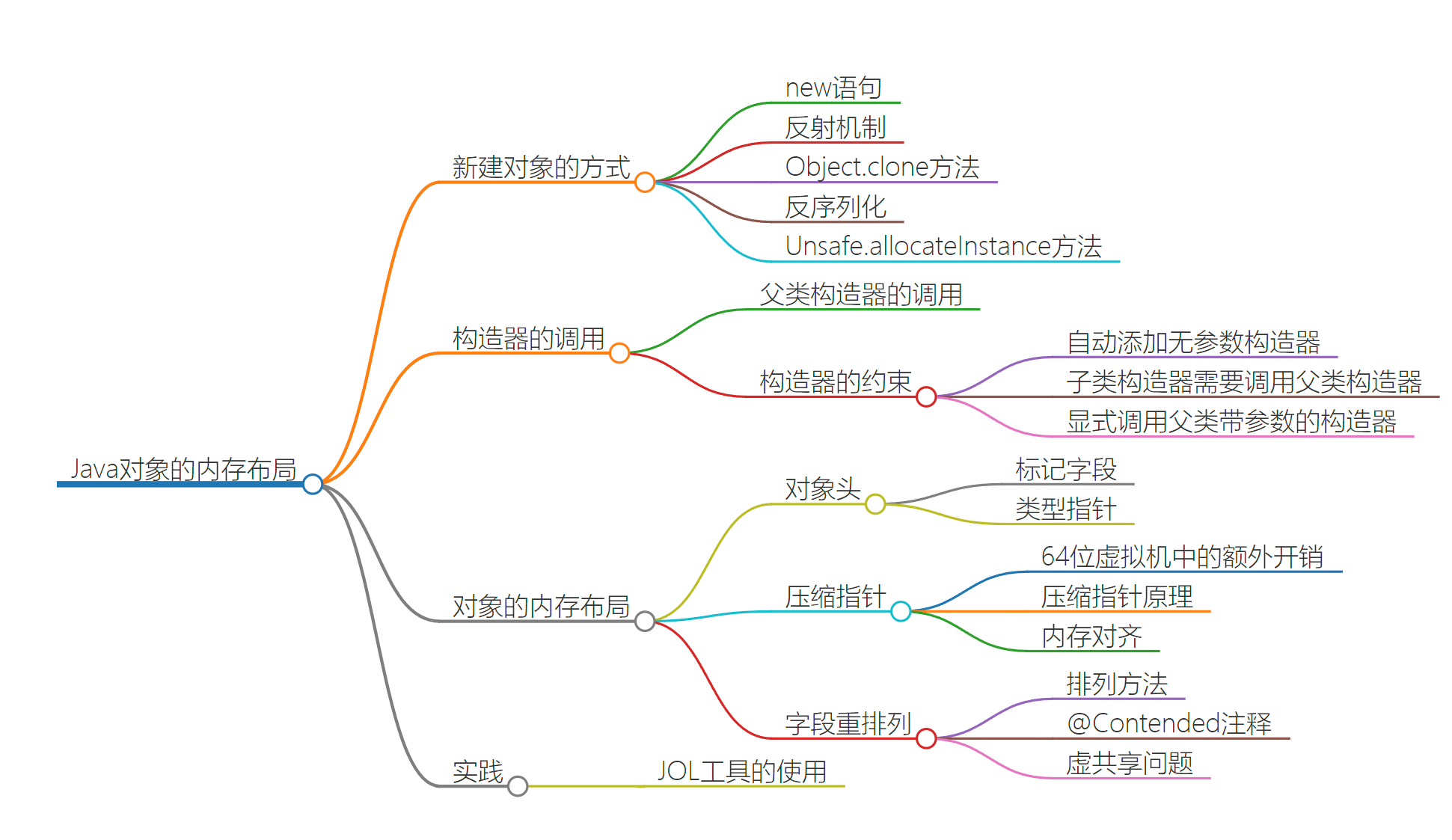
- 对象
- 对象头
- 标记字段,记录有关这个对象运行数据,哈希码,GC,所信息
- 类型指针,指向该对象的类
- 对象头
GC实现
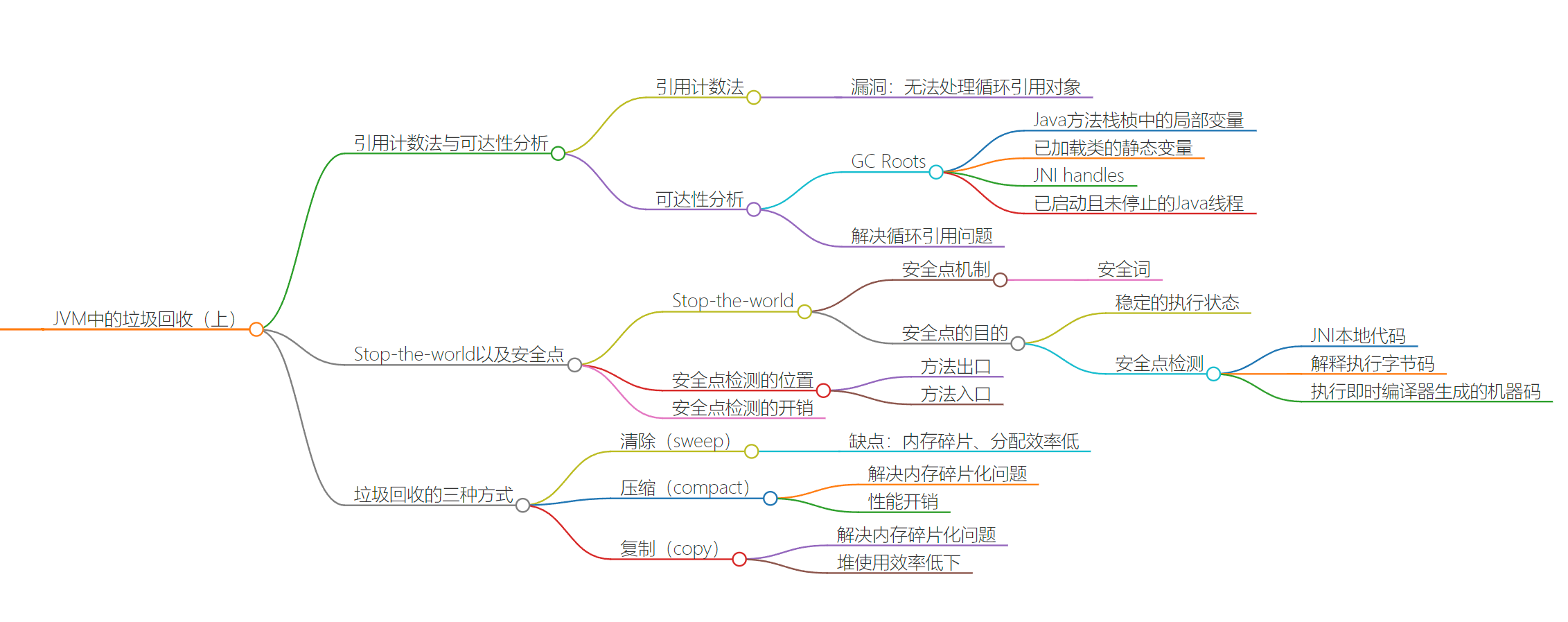
- 引用计数法
- 一个引用被赋值过,则这个对象引用计数+1
- BUG:如果AB对象互相引用,则死循环,永远不会回收了
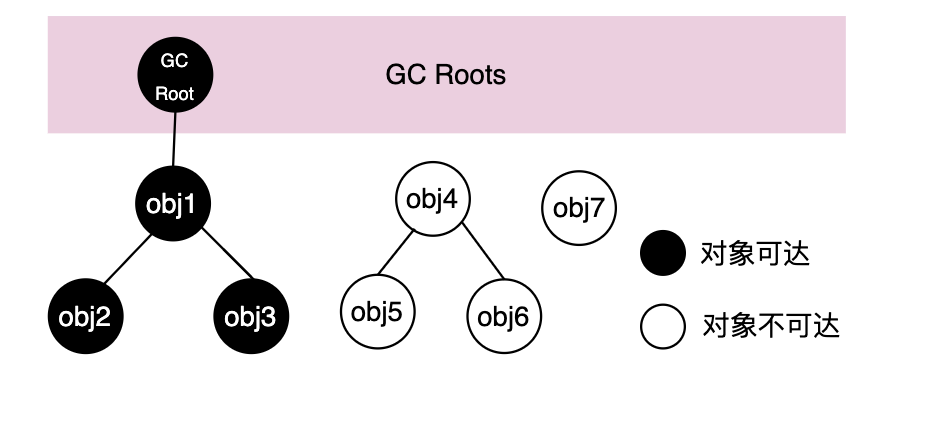
- 可达性分析
- 将GC Roots作为存活对象合集 live set
- 将所有能被引用到的对象加入到集合中,这个过程称为mark
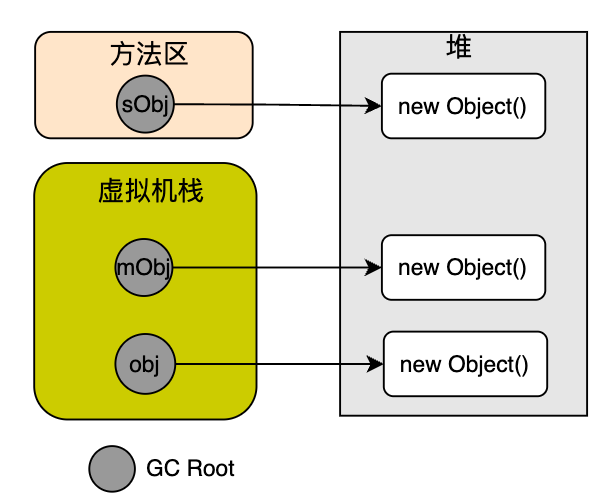
- GC Roots代表由堆外对堆内的引用
- Java方法栈帧的局部变量
- 已加载的类静态变量
- JNI handlers
- 已启动但未停止的线程
- Stop-the-world
- GC pause 停止其他非垃圾回收的线程,直到GC完成
- 通过safepoint机制实现
- 清除过程
- sweep 将死亡对象的内存标记为空闲,记录到空闲列表中,这样子每次初始化对象的时候,就会从这里写入
- 问题:
- 造成空洞数据
- 分配效率低,要逐个访问列表的项,查询能刚好放下对象的内存空间
- 压缩
- 将存活的对象聚集到起始位置中
- 性能开销大
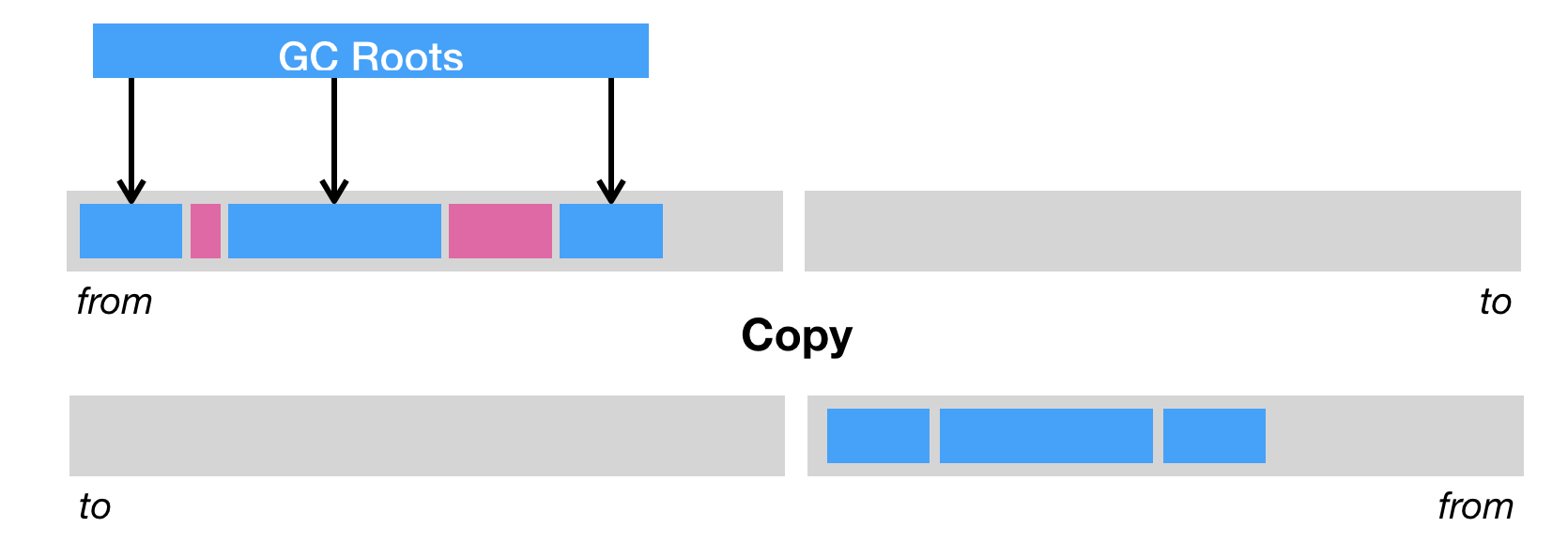
- 复制
- 将内存分为两等分,分别用from to指针维护,每次复制的时候,就把存活的对象复制到to区,实现压缩的效果
- 但这样子的话,就始终需要有空闲的区用来GC复制
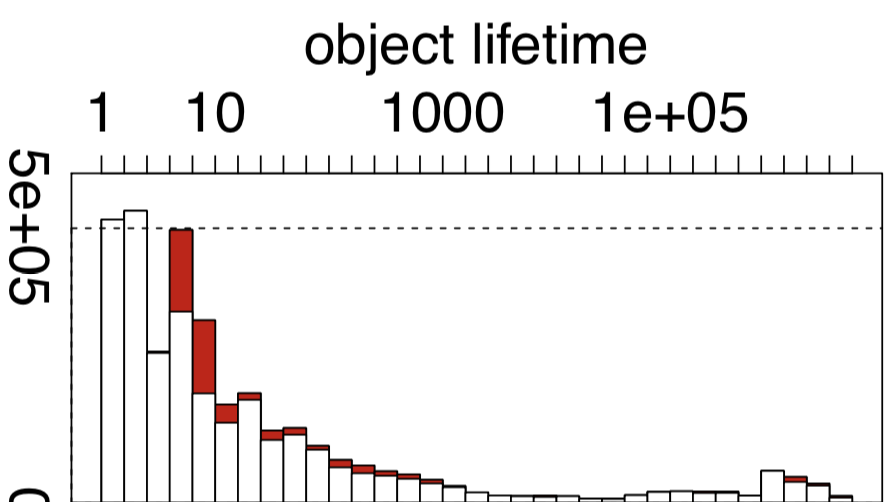
- 对象生命周期分析图
- 绝大部分对象都是只存活一段时间的
- 针对这个情况
- 产生了老年代和新生代的想法
- 新生代存储刚创建的对象
- 老年代存储存活时间够长的对象
新生代中
- Eden区
- 两个大小相同的survivor区 【这个也就是复制的 from to 实现内容】
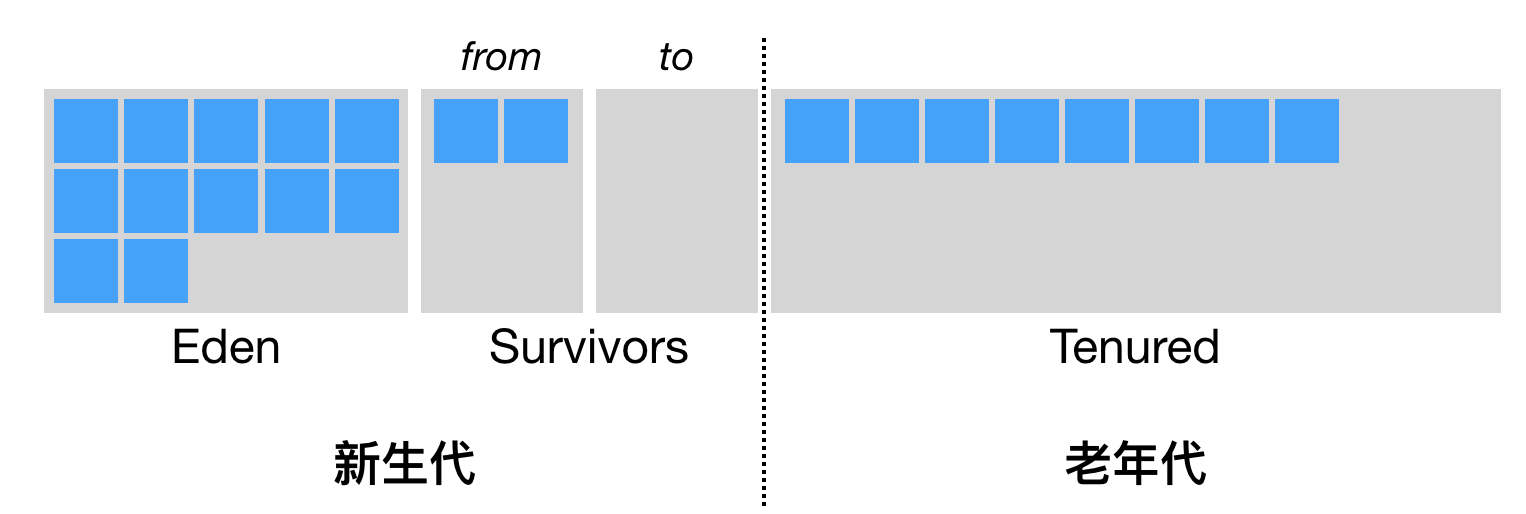
如果eden区满了,触发Minor GC
- 存活下来的对象晋升到survior区
- Eden区的from to指针会进行复制
- 然后再交换指针,保证下次复制时to的空间一定是空的
同时在survivor区中会记录复制次数
- 如果超过15次 MaxTenuringThreshold ,对象晋升到老年代
- 如果survivor单个区超过了50% targetSurvivorRatio ,较高复制次数对象晋升老年代
问题
- 如果老年代持有了新生代对象,那不得对老年代GCROOTs进行扫描?
- 解决方案:
- Card Table 卡表
- HotSpot 给出的解决方案是一项叫做卡表(Card Table)的技术。该技术将整个堆划分为一个个大小为 512 字节的卡,并且维护一个卡表,用来存储每张卡的一个标识位。这个标识位代表对应的卡是否可能存有指向新生代对象的引用。如果可能存在,那么我们就认为这张卡是脏的。
- 每次GC的时候扫描卡表里面的脏卡数据就可以
- 完成扫描后清理脏卡的标志位
- Card Table 卡表
常见GC场景
- CMS 采用的是标记 - 清除算法,并且是并发的。除了少数几个操作需要 Stop-the-world 之外,它可以在应用程序运行过程中进行垃圾回收。在并发收集失败的情况下,Java 虚拟机会使用其他两个压缩型垃圾回收器进行一次垃圾回收。由于 G1 的出现,CMS 在 Java 9 中已被废弃[3]
- G1(Garbage First)是一个横跨新生代和老年代的垃圾回收器。实际上,它已经打乱了前面所说的堆结构,直接将堆分成极其多个区域。每个区域都可以充当 Eden 区、Survivor 区或者老年代中的一个。它采用的是标记 - 压缩算法,而且和 CMS 一样都能够在应用程序运行过程中并发地进行垃圾回收。
Java内存模型
- 重排序
- 在多线程情况下可能出现编译器重排序导致的数据竞争。这时就需要使用volatile来禁止重排序。
- 在单线程情况下,要给程序顺序执行的假象,即重排序的结果也要和执行顺序一致
- 通过内存屏障实现隔离 memory barrier实现
- 这些内存屏障会限制即时编译器的重排序操作。以 volatile 字段访问为例,所插入的内存屏障将不允许 volatile 字段写操作之前的内存访问被重排序至其之后;也将不允许 volatile 字段读操作之后的内存访问被重排序至其之前。
synchronized实现机制
- 执行synchronized块时
- 生成monitorenter、monitorexit指令,这两个都会对加解锁的锁对象进行操作
- 执行monitorenter时,
- 如果对象计数器为0,代表没有线程引用过,
- 设置锁对象的持有线程为当前线程,并计数+1
- 如果对象计数器为0,代表没有线程引用过,
- 执行monitorexit
- 对象计数器-1
- 减到0的时候,对象锁释放
- 对象计数器的目的是为了允许统一线程重复获取锁,可重入的实现
- 比如说一个类中有多个synchronized 方法,他们之间的相互调用,本质上都是对同一个对象的锁重复加解锁操作
- 重量级锁
- Java 虚拟机会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程。
- 为了尽量避免昂贵的线程阻塞、唤醒操作
- Java 虚拟机会在线程进入阻塞状态之前,以及被唤醒后竞争不到锁的情况下,进入自旋状态,在处理器上空跑并且轮询锁是否被释放。如果此时锁恰好被释放了,那么当前线程便无须进入阻塞状态,而是直接获得这把锁。
- 对于 Java 虚拟机来说,它并不能看到红灯的剩余时间,也就没办法根据等待时间的长短来选择自旋还是阻塞。
- Java 虚拟机给出的方案是自适应自旋,根据以往自旋等待时是否能够获得锁,来动态调整自旋的时间(循环数目)。
- 如果之前不熄火等到了绿灯,那么这次不熄火的时间就长一点;如果之前不熄火没等到绿灯,那么这次不熄火的时间就短一点。
- 轻量级锁
- 多个现场不同时间段请求同一把锁,没有竞争
- 通过轻量级实现
- 对象头中的标记字段(mark word)
- 它的最后两位便被用来表示该对象的锁状态。
- 00 代表轻量级锁,
- 01 代表无锁(或偏向锁)
- 10 代表重量级锁,
- 11 则跟垃圾回收算法的标记有关。
- 它的最后两位便被用来表示该对象的锁状态。
- 使用CAS compare and swap机制替换锁对象的标记字段
- CAS 原子操作
- 比较锁对象的标记字段的值是否为当前锁记录的地址。
- 如果是,则替换为锁记录中的值,也就是锁对象原本的标记字段。
- 此时,该线程已经成功释放这把锁
- 偏向锁
- 始终只有一个线程在请求同一把锁
- Java 虚拟机会通过 CAS 操作,将当前线程的地址记录在锁对象的标记字段之中,并且将标记字段的最后三位设置为 101
- 每次请求锁的时候
- 判断锁对象标记字段中,如果都满足则直接返回
- 最后三位是否为 101
- 是否包含当前线程的地址
- 以及 epoch 值是否和锁对象的类的 epoch 值相同
- 每个类中维护一个 epoch 值,你可以理解为第几代偏向锁。当设置偏向锁时,Java 虚拟机需要将该 epoch 值复制到锁对象的标记字段中
- 在宣布某个类的偏向锁失效时,Java 虚拟机实则将该类的 epoch 值加 1,表示之前那一代的偏向锁已经失效。而新设置的偏向锁则需要复制新的 epoch 值
- 判断锁对象标记字段中,如果都满足则直接返回
语法糖实现
- 类型擦除
- 那便是 Java 程序里的泛型信息,在 Java 虚拟机里全部都丢失了。这么做主要是为了兼容引入泛型之前的代码
- 对于限定了继承类的泛型参数,经过类型擦除后,所有的泛型参数都将变成所限定的继承类。也就是说,Java 编译器将选取该泛型所能指代的所有类中层次最高的那个,作为替换泛型的类。
class GenericTest<T extends Number> {
T foo(T t) {
return t;
}
}
- 桥接方法
- 为了保证编译而成的 Java 字节码能够保留重写的语义,Java 编译器额外添加了一个桥接方法。该桥接方法在字节码层面重写了父类的方法,并将调用子类的方法
class Merchant<T extends Customer> {
public double actionPrice(T customer) {
return 0.0d;
}
}
class VIPOnlyMerchant extends Merchant<VIP> {
@Override
public double actionPrice(VIP customer) {
return 0.0d;
}
}
- foreach
- 对于数组,就是数组的从0开始访问
- 对于Iterator就是调用iterator方法进行调用
- switch的实现
- 可以理解为一个哈希桶
- 会switch里的字符串变为int值,也就是输入字符串的哈希值进行比较
- 字符串哈希可能还会碰撞,所以还需要通过string.equals逐个比较字符串判断
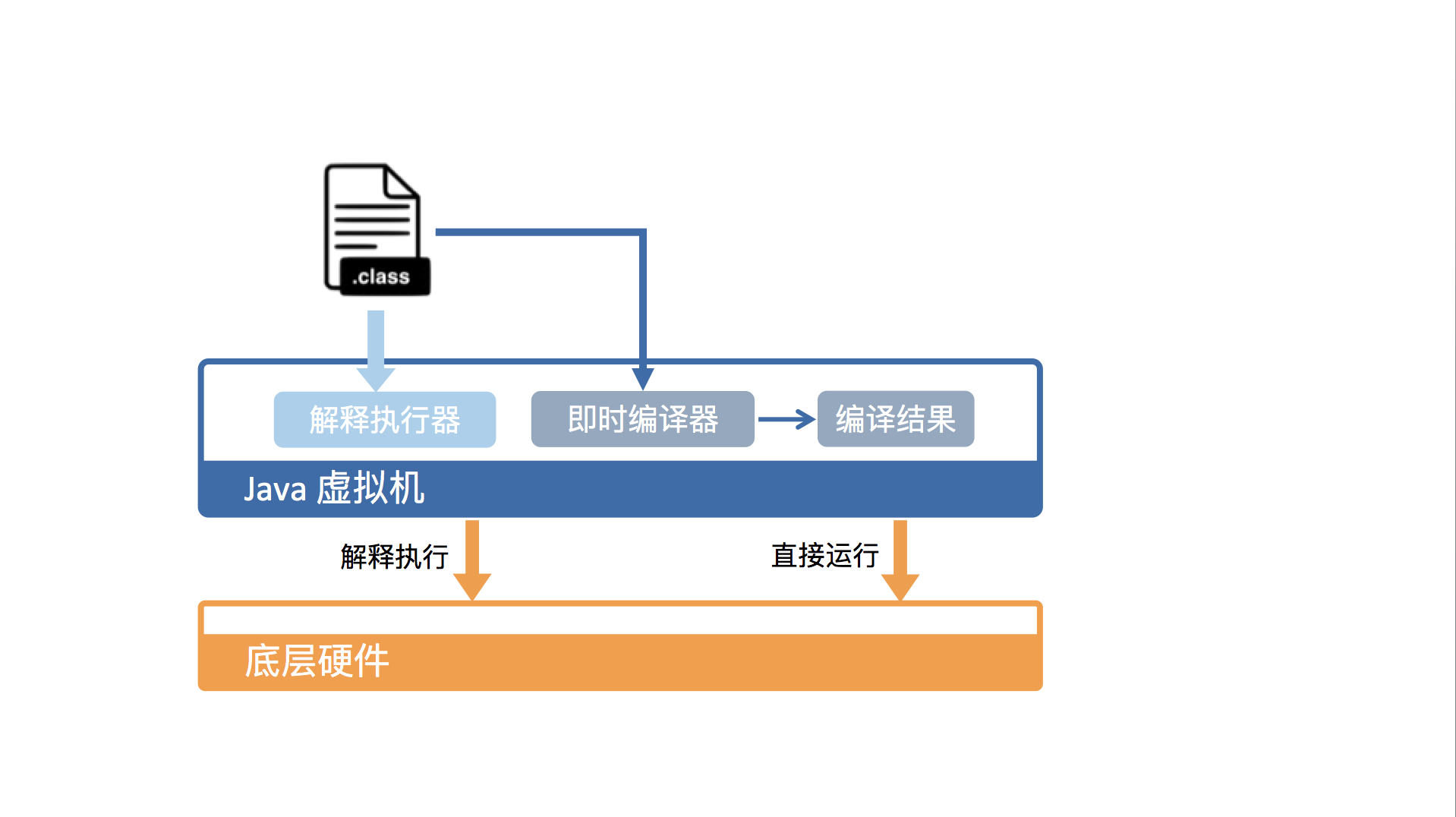
即使编译
- HotSpot虚拟机包含多个即时编译器C1,C2,Graal
- Graal是实验性质的,可用于替换C2,一般理解C1,C2即可
- 即使编译的触发
- 通过方法的调用次数和循环回边的执行次数来触发
- 在不启用分层编译的情况下,当方法的调用次数和循环回边的次数的和,超过由参数 -XX:CompileThreshold 指定的阈值时
- 另外这里调用次数并不是一个精确值,只需要知道这个是热点方法即可
- (使用 C1 时,该值为 1500;使用 C2 时,该值为 10000),便会触发即时编译。
- 简单来说C2在处理上,增加了大量剪枝,更为激进的优化方式
逃逸分析
- 分析当前对象作用域是否超出当前方法或线程,再做对应的对象优化
- 栈上分配
- 如果一个对象不会作用于方法外,则可以直接分配到栈上,而不是堆上
- 锁消除
- 如果是单线程调用,则可以调用无用的锁
- 标量替换
- 将原本分配到堆上的对象拆成多个基础数据类型到栈上,进一步减少堆空间的使用
- 栈上分配
- 字符池优化
- 通过在堆中共享字符池,重用字符串对象,减少内存占用和提高共用
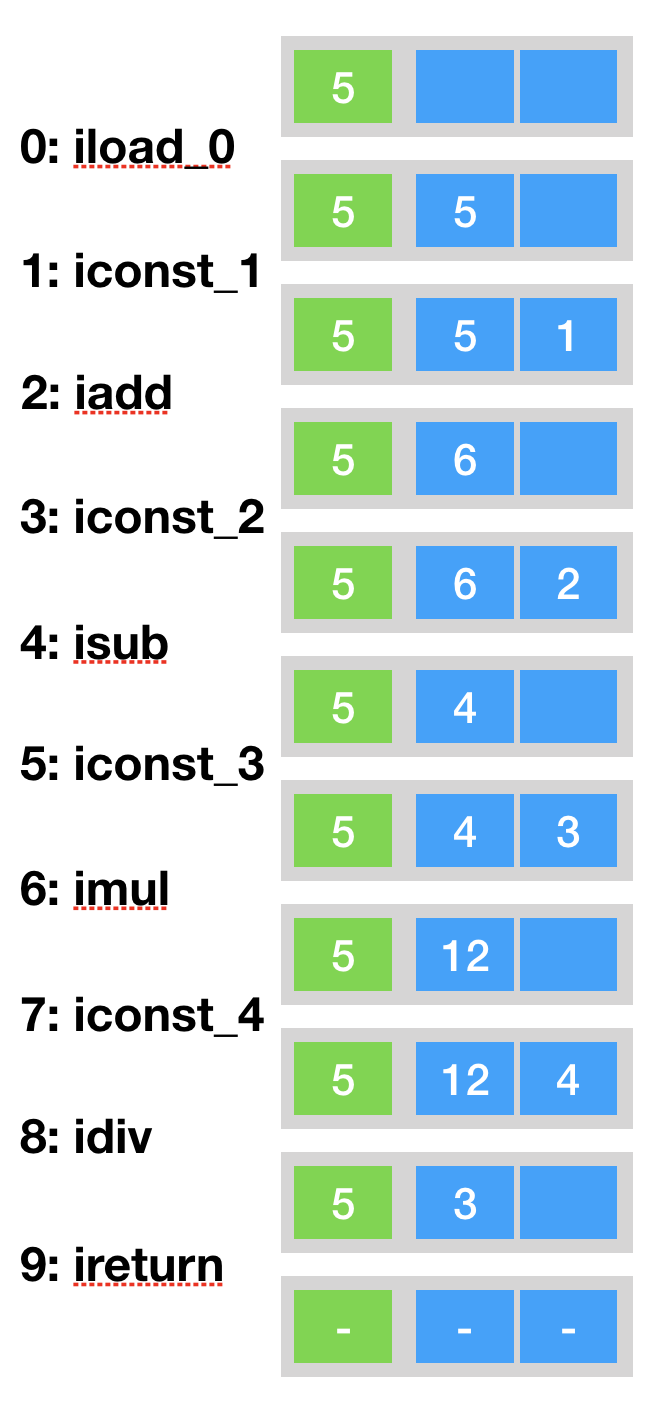
Java字节码
- 对象构成
- 操作数栈
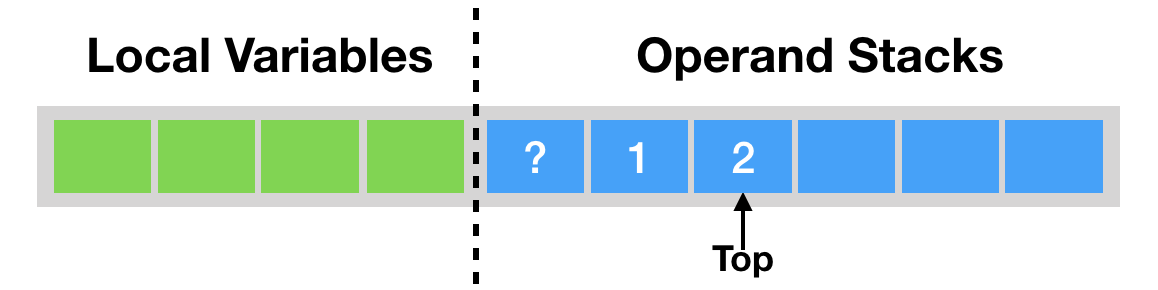
- 局部变量区【方法堆帧中】
- 将计算的结果缓存在局部变量区

- 将计算的结果缓存在局部变量区
- 操作数栈
- 组合调用图
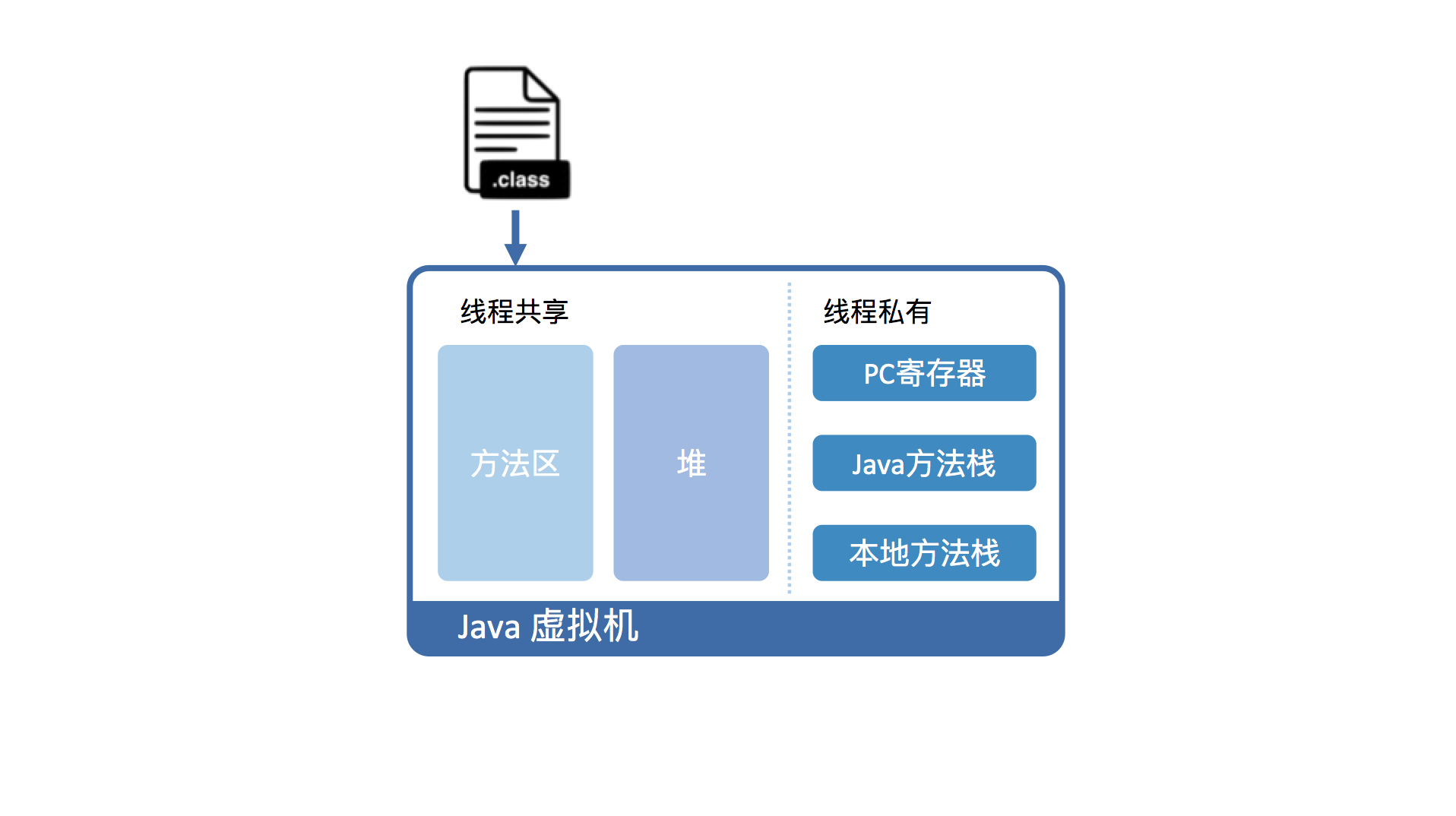
JVM内存结构
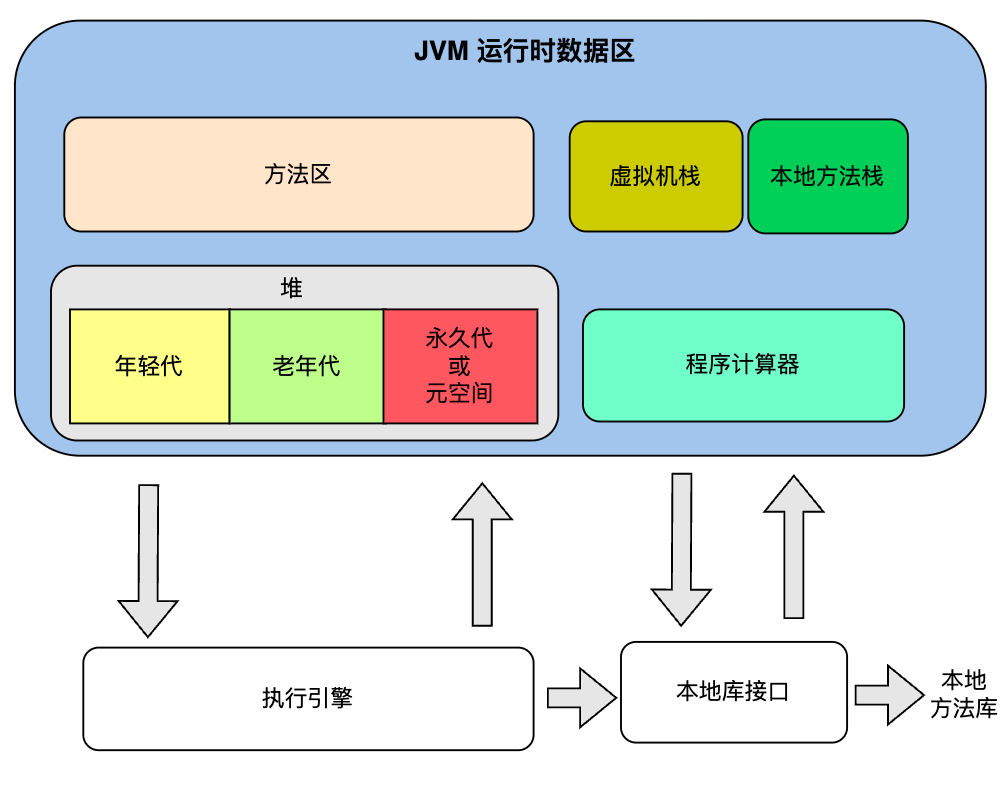
- 方法区
- 堆的逻辑区域,线程共享,存储常量、静态变量,编译后的代码缓存
- 堆
- 存放对象实例和数组
- JDK8中还有元空间,存放类信息、方法信息、常量等
- 程序计数器
- 存储当前线程执行的字节码的行号指示器
- 每个线程都有自己的程序计数器
- 虚拟机栈
- 每个Java方法执行的时候都会有自己的栈帧
- 栈帧存储局部变量表、操作数栈、动态链接、方法出口等
- 一般是方法执行完后自动清理
- 本地方法栈【native方法】
- 调用本地代码
- 即通过JNI调用非Java代码,线程私有
- 同样执行完后清理
volatile的实现
https://www.cnblogs.com/vipstone/p/18044839
- 首先是工作时内存
- 每个线程有自己内存备份
- 然后会有一个公共内存
- 这里就会有个问题
- 如果线程一改了自己的内存,但线程2不能感知到,因为它拿的还是之前的备份
- 第一个特性可见性就是为了解决这个问题(咋解决的啊
- 通过lock前缀命令实现,优先回写到主内存,非常快
- 然后再通过mesi协议向其他内存广播失效,要求重新读取最新的内存数据
- modify,exclusive,share,invalid
- 然后是重排序问题
- if lock is null 1
- synclock lock 2
- new lock 3
- synclock lock 2
- 正常执行没问题,但如果重排序了,就会变成132的顺序
- 这里如果是单线程无并发确实没问题
- 但如果是多线程下,线程a初始化了对象,线程b在初始化成功前通过了1,就变成两个线程都前new lock了
- if lock is null 1
- 解决方案:内存屏障
- 写屏障
- 写屏障是等写命令
- 读屏障
- 都是等命令必须全部执行完后,才允许往下走
- 区分读屏障是等读命令
- 写屏障
CMS的技术原理
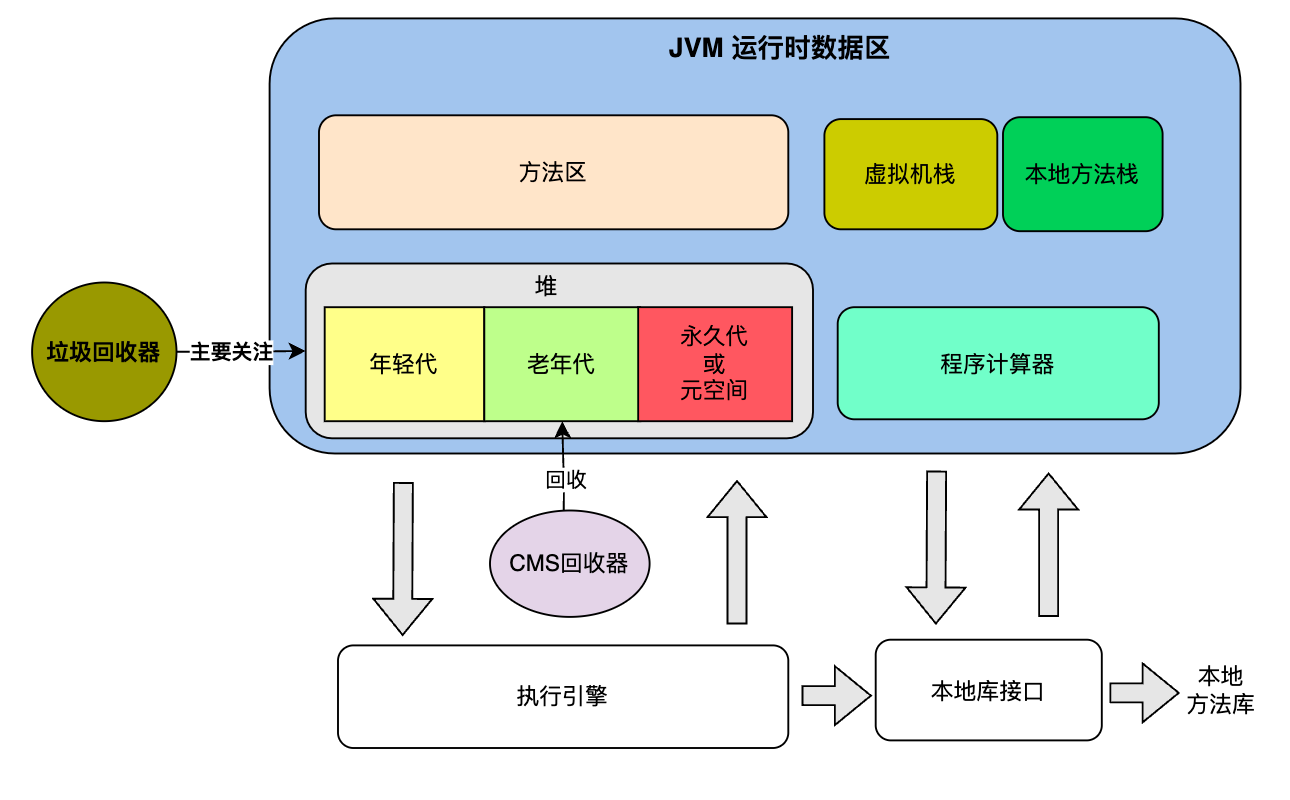
- 聊一聊“标记”
- 三色标记法
- 白色 表示未访问过
- 灰色 表示被标记为存活,但引用的对象还没有全部扫描过,灰色对象可能引用白色对象
- 黑色 表示标为存活,且该对象的所有引用都扫描过了,黑色对象不会引用任何白色对象
- 三色工作流程
- 初始化时,所有标记为白色
- 所有GCRoots 标记为灰色
- 从集合选一个灰色对象,标记为黑色,并将它引用的所有白色标记为灰色,且放到灰色集合中
- 重复3步骤,直到灰色集合为空
- 最后所有的黑色对象是活跃的,白色是垃圾
- 三色标记法
- CMS全称 Concurrent Mark Sweep 并发标记清除
- 减少GC暂停时间、实现应用线程和GC线程并发执行
- 用于老年代的垃圾回收,使用的标记-清除算法
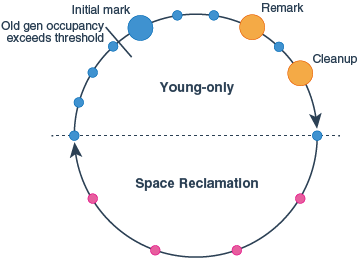
- 步骤
- Initial Mark 会stop the world
- Concurrent Mark 并发标记
- Remark 重复标记 会暂停
- Concurrent Sweep 并发清除
- Resetting 重置
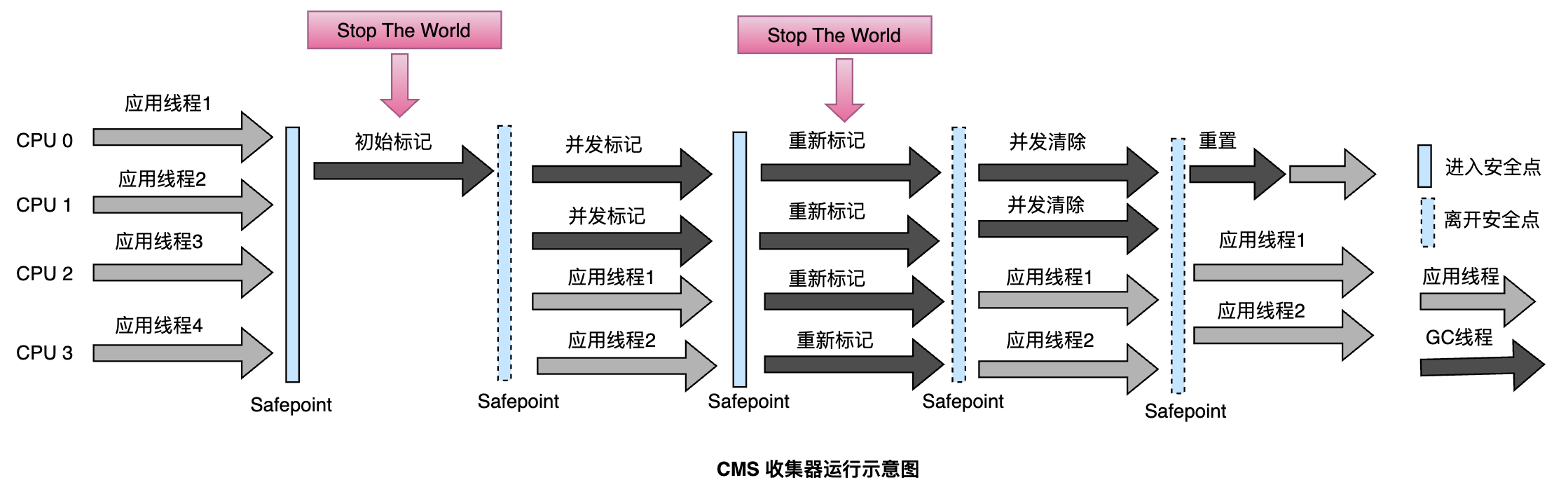
- 初始标记阶段
- 扫描GCRoots 和 GCRoots直接关联的对象
- 通过OopMap (Object-Oriented Programming Map)数据结构,用于在GC期间快速定位堆中的对象引用OOP (Object-Oriented Pointer)
- 为什么要stop the world
- 确定Roots集合,避免被修改
- 避免并发读写问题
- 并发标记
- 在有了上面的GC Roots后
- 鬓发遍历可以追踪到的所有可达的存活对象
- 同时用于此时应用线程是持续更新的,可能有以下变化
- 新生代晋升
- 老年代直接分配
- 老年代引用关系变化
- 为了记录以上的变化
- 通过后置写屏障Write Barrier,确保变更记录到卡表 card table中,用于标记这项卡表的内存是脏 dirty,以便后续处理
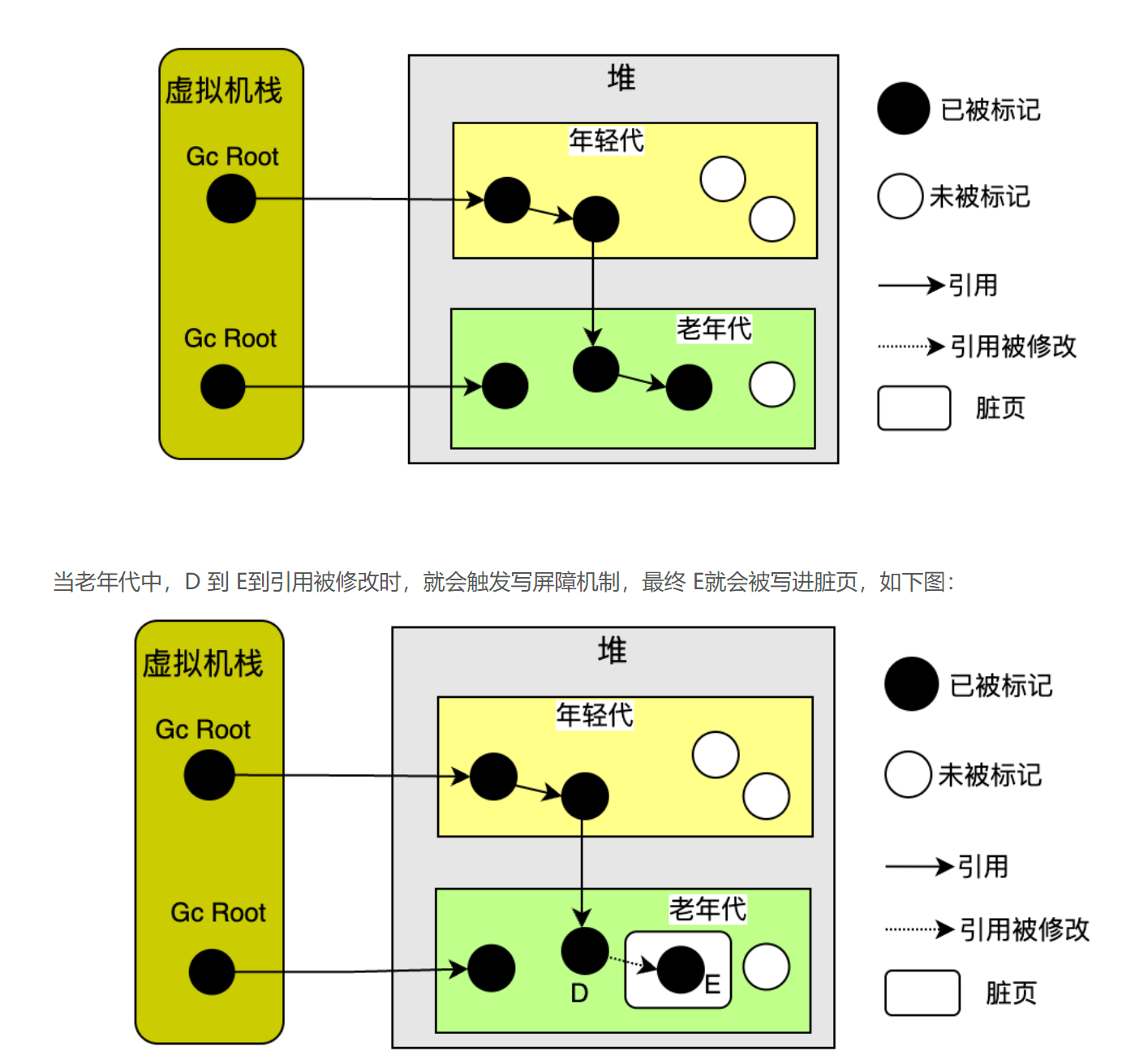
- 通过后置写屏障Write Barrier,确保变更记录到卡表 card table中,用于标记这项卡表的内存是脏 dirty,以便后续处理
- Remark 重新标记【STW】
- 并发预清理,尽量减少需要重新标记的工作量
- 修正标记结果,为了避免应用程序这段时间的变更,需要STW,来修改这些标记结果
- 处理card table里面的脏卡数据
- 处理最终可达对象
- 处理弱引用过、软引用等等
- 并发清除
- 清理标记为死亡的对象
- 清除完后,使用空闲列表 free-list 将未标记的内存收集起来,用于下次的内存分配使用
G1原理
忘记以前的eden survivor、old、permanent把,拥抱新的变化
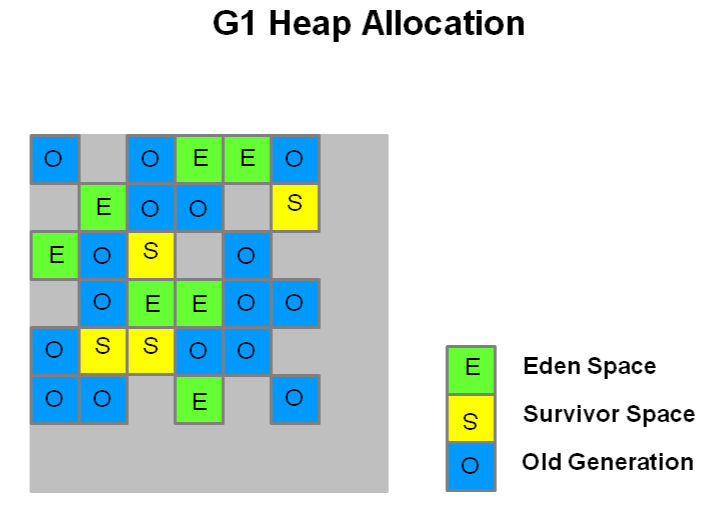
将堆分为若干个区域(Region)
当然它依然有分代的概念
新生代GC时依旧需要STW,晋升时拷贝到survivor 或者old
老年代也会有多个Region区域的概念
- 每次GC的时候,就是把对象从1个区域复制到另外一个区域
- 解决了CMS的内存碎片的问题
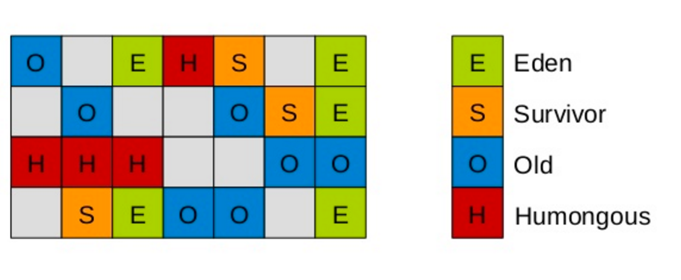
G1中有个特殊区域,叫做Humongous
- 当一个对象内存占用超过50%以上时,视为巨型对象
- 直接分配到巨大区 H区
- 会找连续的H区进行存放
- 如果找不到,触发FullGC
YoungGC
- 主要是对Eden区进行GC,在Eden使用完时触发
- Eden挪到survivor
- 如果survivor不够用,挪到old
- 相比于以前的GC主要是合理利用各个周期的资源,弱化分代的该你那
- 以分区为单位,对象分配通过卡表
- 优先GC垃圾最多的Region,这也就是Garbage First的名义含义
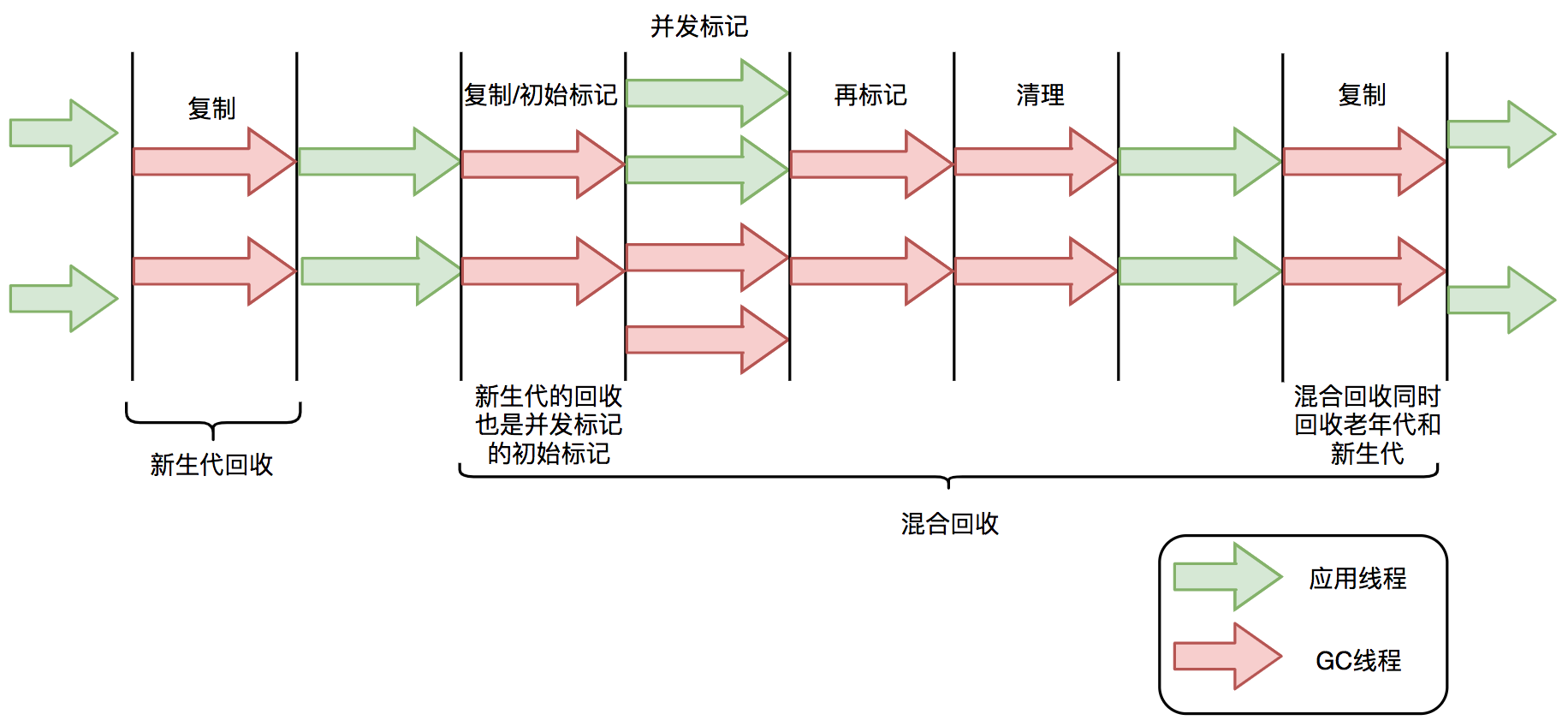
- 初始标记 STW
- REMARK STW
ZGC原理
- JDK11退出,STW不超过10ms
- STW时间不会随着堆增长而增加
- 支持8MB~4TB的堆
- ZGC也用的是标记-复制方法,但是在标记、转移、重定位几乎是并发的,这也是为什么STW在10ms内
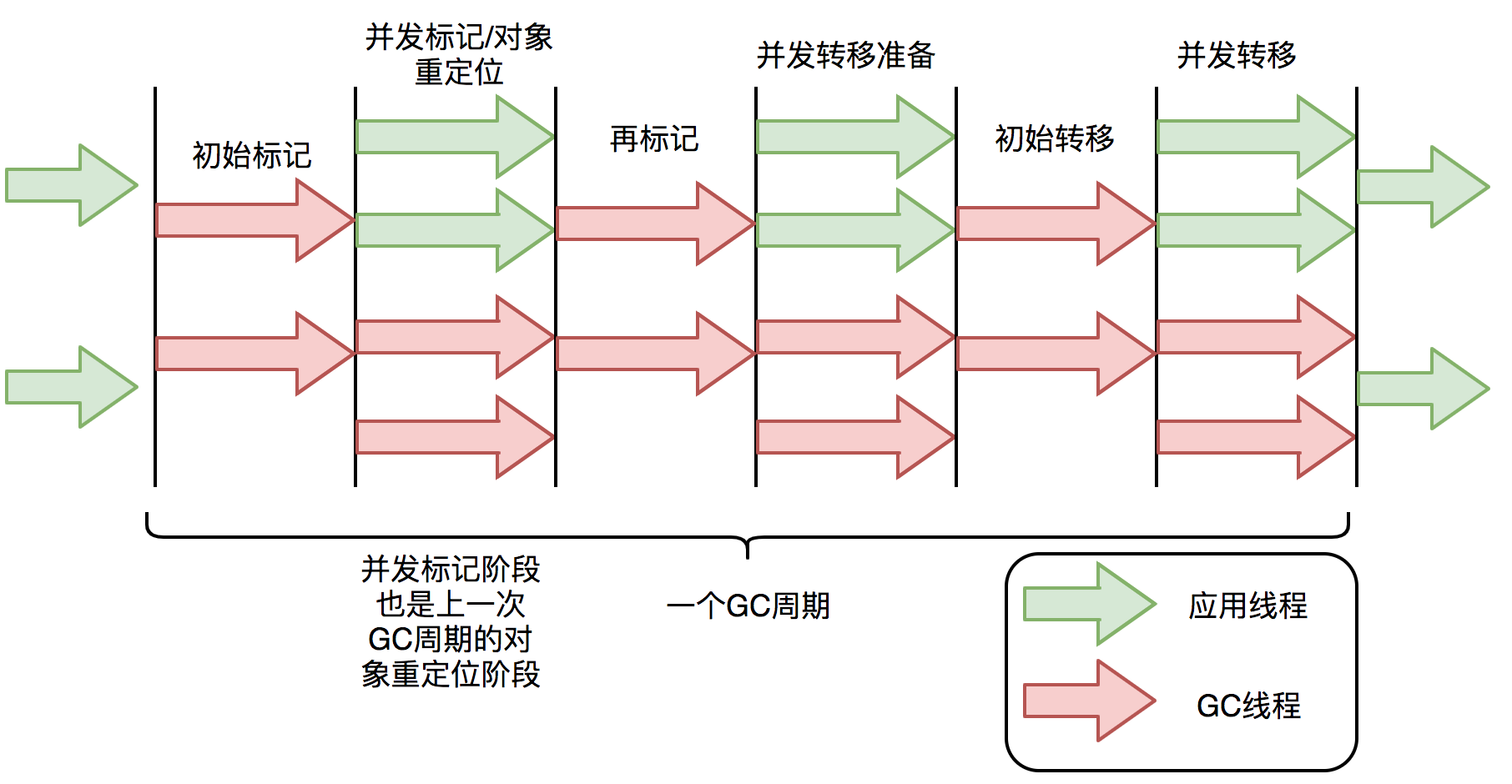
- 核心关键
- 通过着色指针 & 读屏障解决了转移过程中访问对象的问题
- 并发转移也就是GC线程在转移对象的时候,应用现场也在访问对象
- 假如对象发生转移,但是对象地址未更新,就会导致应用线程读的是老数据
- ZGC中,应用线程读取时会触发“读屏障”,如果发现被移动了,“读屏障”会更新读出来的指针为对象的新地址
- 通过着色指针 & 读屏障解决了转移过程中访问对象的问题
- 着色指针
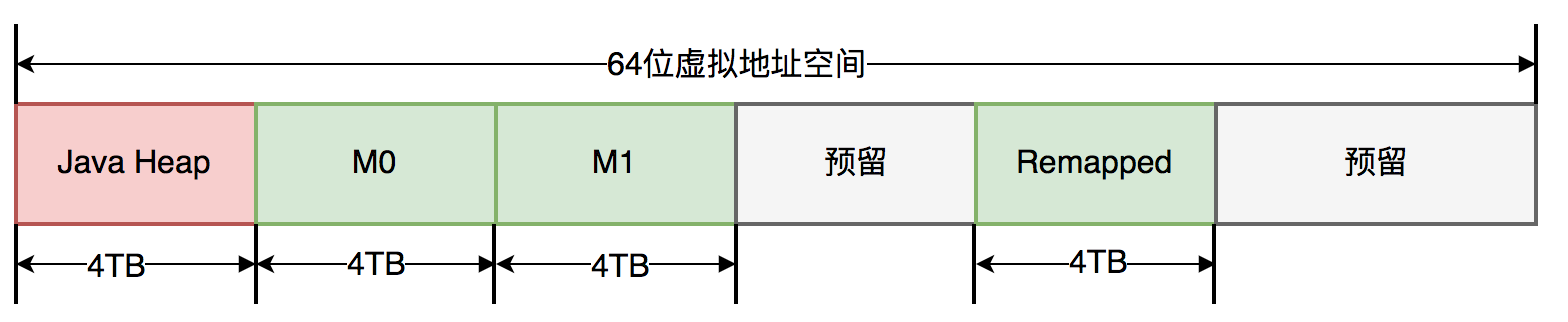
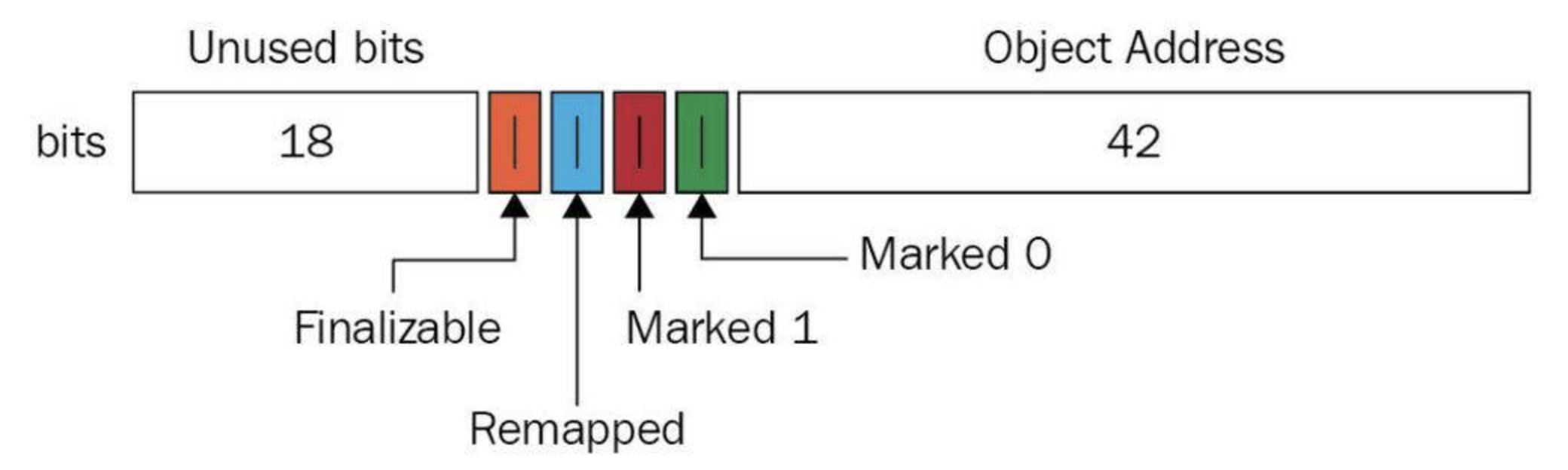
- 在引用指针中增加了四个标记为
- Finalizable
- Remapped
- Marked 0
- Marked 1
- M0和M1会交替使用
- 因为ZGC标记完成后,并不需要等对象重映射完成,可以马上进行下一次GC
- 也就是说两次GC间是会有重叠的
- 简单来说
- 第一次标记都记为Remapped
- 存活的对象视为M0
- 复制存活对象到新的区域,复制完成后
- M0更新为Remapped
- 并记录到转发表中
- 那这里就会有问题了,如果此时有对象访问老的对象地址呢,还没更新呢
- 触发读屏障,修正老的引用到新的对象上,并删除转发表上的记录
- 这个过程成为指针的“自愈”
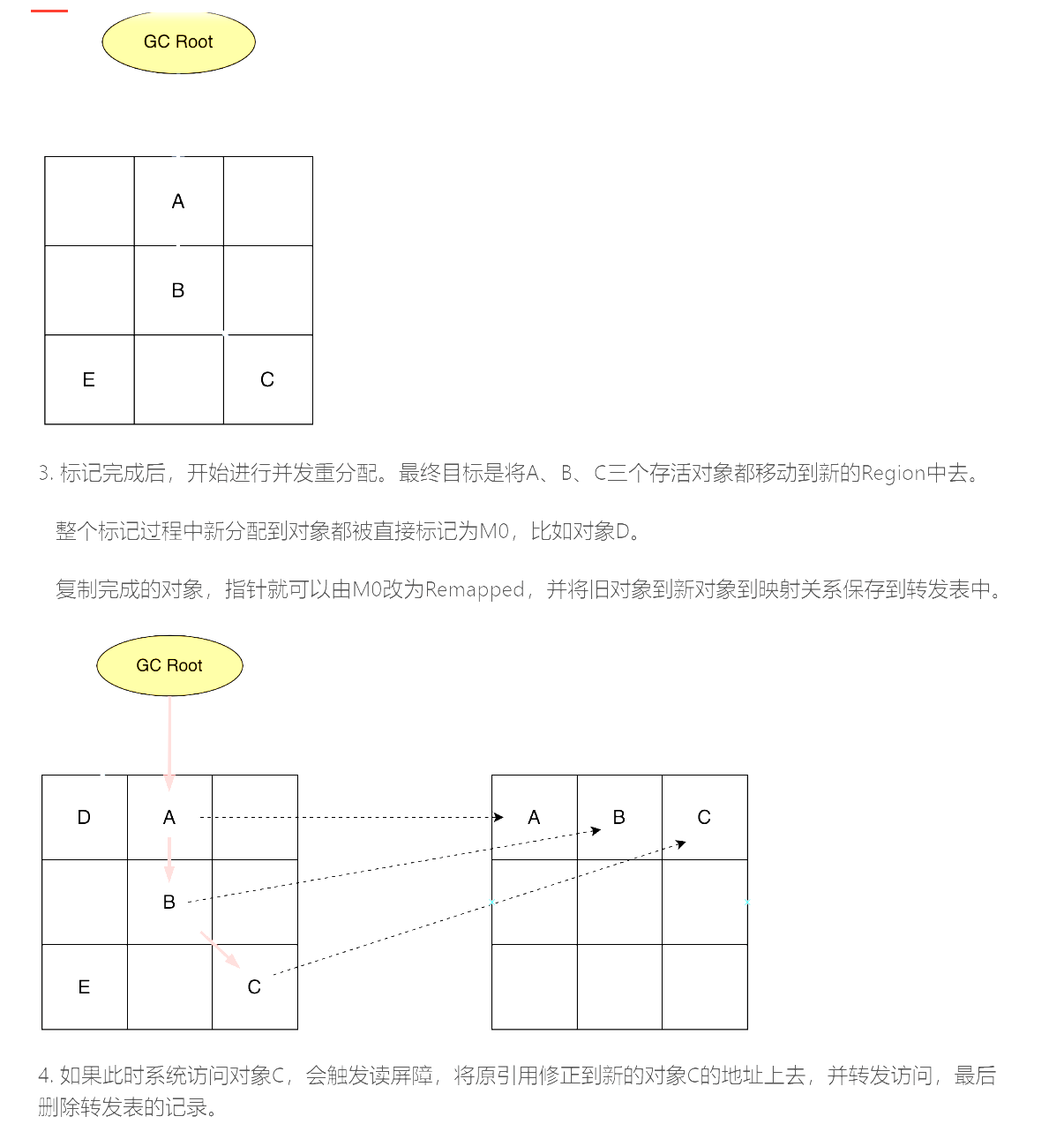
在并发重映射阶段
- 会把这项引用做订正,并删除转发表的记录,相当于指针自愈的定时任务
在下一次并发标记阶段
- 由于上一次GC还没完成,所以Remapped指针此时标记为M1,而不是上次的M0,用来和上一次存活的对象进行区分
读屏障
- JVM在应用代码插入一小段代码
- 当从堆读取对象的时候,会加入读屏障
Object o = obj.FieldA // 从堆中读取引用,需要加入屏障
<Load barrier>
Object p = o // 无需加入屏障,因为不是从堆中读取引用
o.dosomething() // 无需加入屏障,因为不是从堆中读取引用
int i = obj.FieldB //无需加入屏障,因为不是对象引用
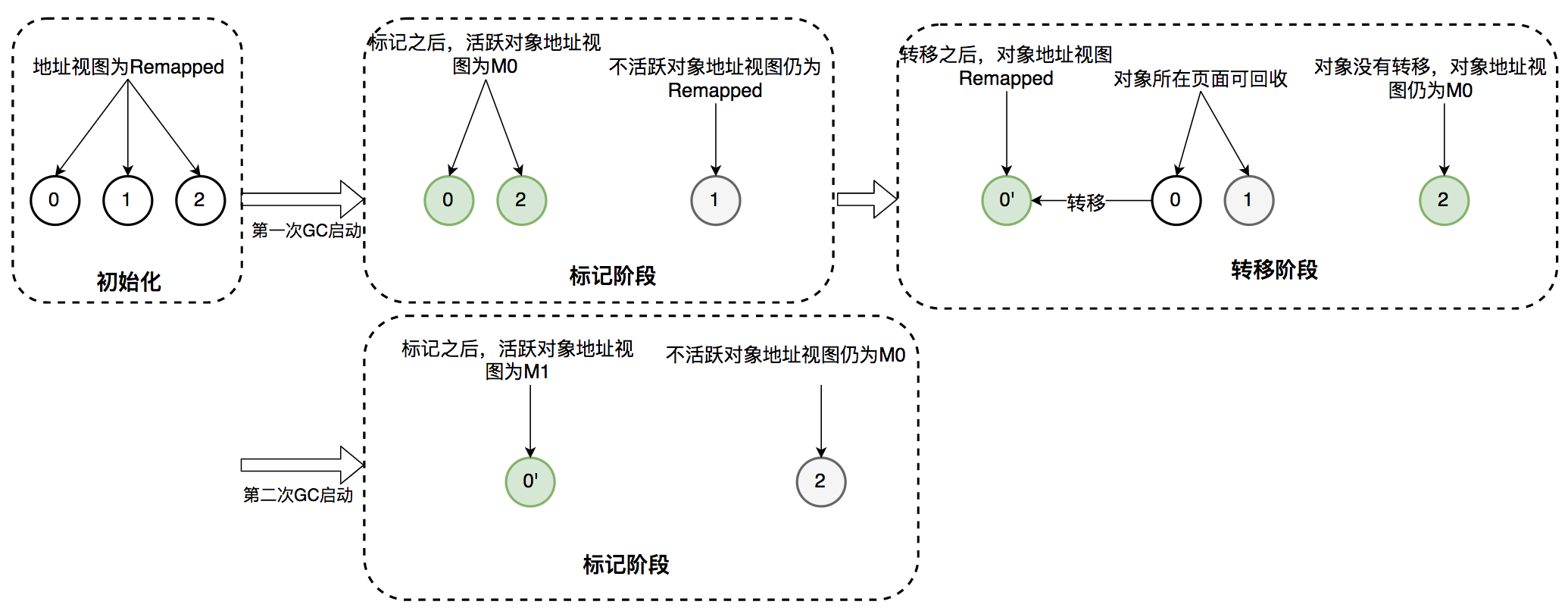
- ZGC回收流程
- 初始化,所有地址视图作为remapped
- 满足GC条件时,触发标记 STW
- 并发标记阶段
- 第一次进入标记视图时,视图为M0,如果对象被GC或者应用线程访问过,从Remapped的对象地址视图更新为M0
- 在标记结束后,要么是M0,要么是Remapped
- 如果是M0,表示活跃,后者则不活跃
- 标记结束 STW
- 并发转移阶段
- 将可回收的,重新标记为Remapped
- 如果对象被GC访问or应用线程访问,对象视图从M0调整为Remapped
- 内存布局
- 也是采用分区域,和G1一样
- 但是Region 或者说Page, 可以动态创建和销毁
- 分为小中大的Region
- 小 2MB 存放小于256KB的对象
- 中 32MB 存放256KB~4MB
- 大 2MB的整数倍,存放4MB以上的大对象,每个大Region只放一个大对象
- 分为小中大的Region
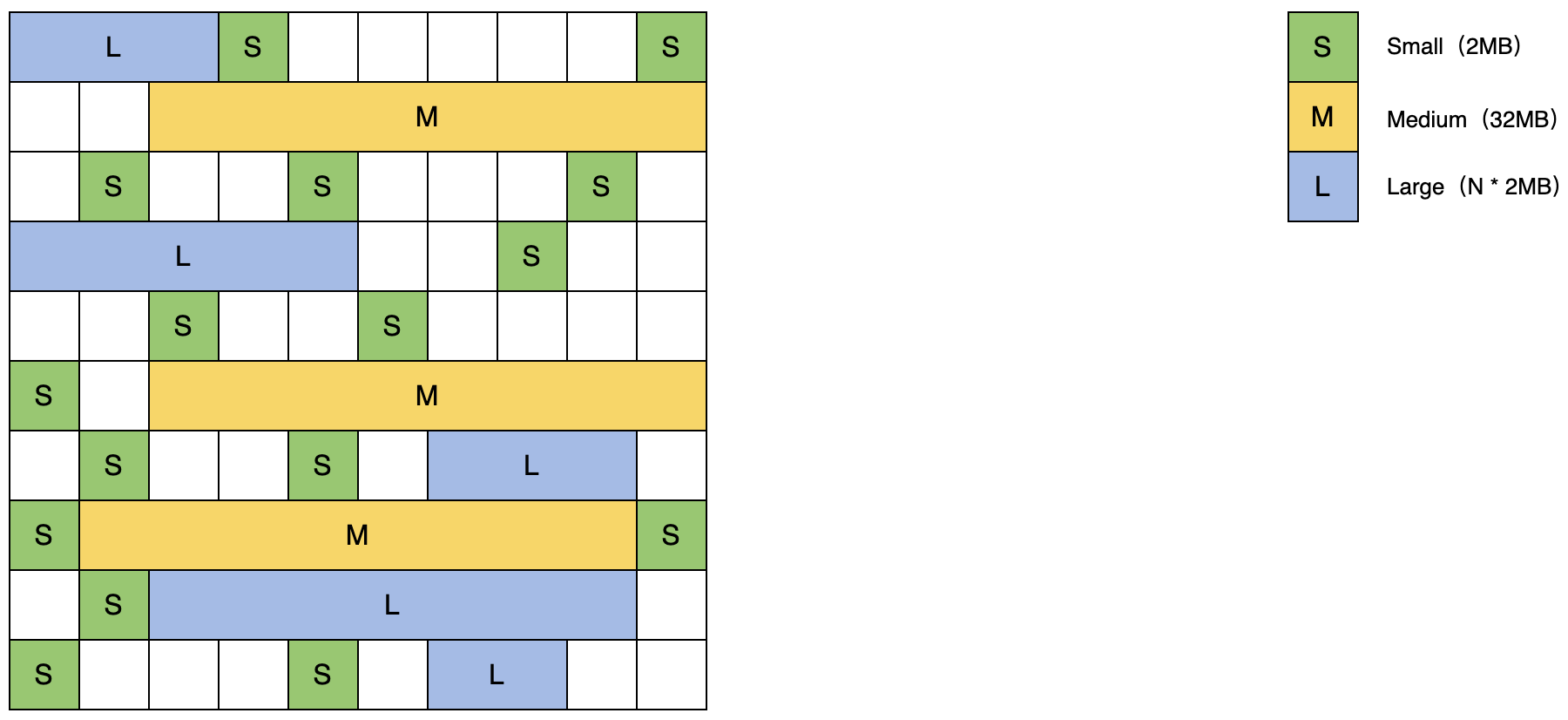
- G1存储了所有的Region信息到卡表中,对于ZGC放弃卡表维护,标记阶段扫描所有的Region
- 如果某个Region要重分配,就放到重分配集合中
场景题
为什么要用双亲委派机制
- JVM在不同类的类名相等时,会通过加载的类加载器是否相等,判断是否同一个类
- 假如没有这个机制的话,那么一个类可能同时被多个类加载器执行,那么就会出现问题
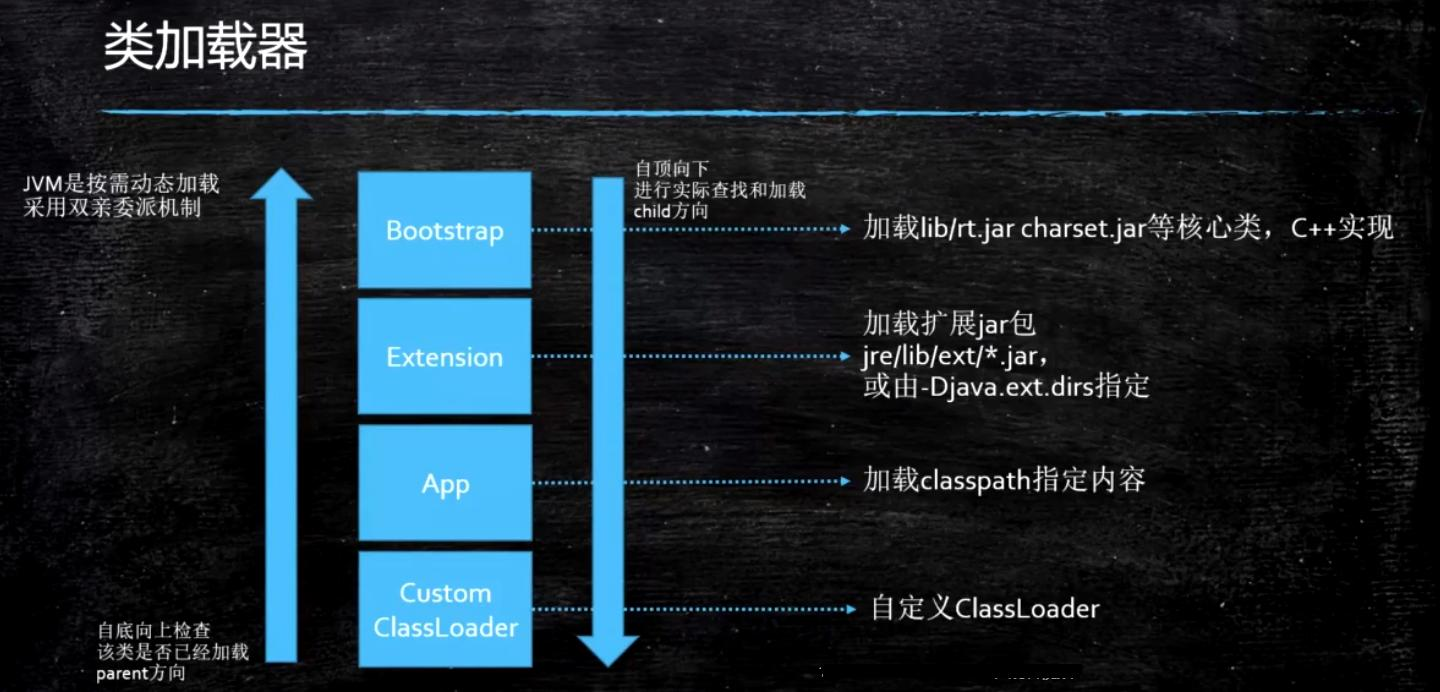
- 此外通过这个机制,可以保证Java官方的类库的类加载安全性,而不用担心呗开发者覆盖
- 同理,如果开发者想要自定义,也可以通过自定义累加器,来实现自己框架的类不会被应用层的覆盖
- 自定义实现的话
- 就要 extends ClassLoader
- 实现findClass的逻辑
- 如果还不想按照双亲委派的类加载顺序,还要重写loadClass
- 就要 extends ClassLoader
GC回收期的发展历史
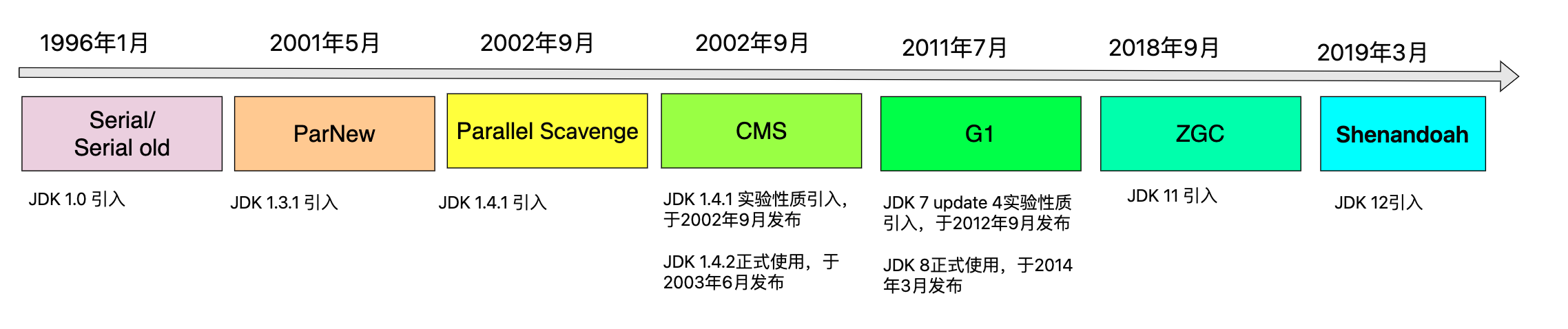
- 标志的几个GC
- JDK1.4 里面的CMS
- JDK1.7 里面的G1
- JDK11 里面的ZGC
问题排查&实战
排查思路
- 确认业务影响
- 有损!!
- 切流下线
- 通过eureka、HSF下线
- 如果涉及变更,代码回滚
- 机器重启 or 手动fullgc
- 变更前保存现场
- 切流下线
- 无损
- 业务增加导致内存增加
- 业务无变更
- 周期性增长
- 排查是否有定时任务
- 偶发性
- 看看能不能复现
- 缓慢增长
- 要看内存的实际情况
- 周期性增长
- 有损!!
保留现场方法
- headdump
- 命令转存
- jmap -dump:format=b,file=head.bin xxPID
- jcmd GC.head_dump filename=heap.bin
- PID可以通过top,或者jcmd -l获取
- 启动参数
- 配置OOM时自动生成
- 编程生成
- 命令转存
- 查看启动参数 ps -ef | grep java
- GC日志
- 通过命令参数打开 +PrintGCDetails
- 内存栈
- jstack xxPID xx.log
- jcmd xxPID xx.print>xx.log
- linux日志
- 如果jvm进程没了,排查是否被kill掉了
- grep /var/log/kern.log* -ie kill
- 如果jvm进程没了,排查是否被kill掉了
- jvm溢出日志
- 查看日志有无OOM字样
hsf未开启预热导致线程池满问题
- 问题现象
- hsf线程池满
- hsf.log出现大量超时
- 排查思路
- 抓取gc.log 丢给GC分析网页进行分析
- 分析过程
- 频繁的ygc
- 每次ygc时,导致老年代增加
- 老年代持续增加,直到fullgc
- 在中间触发了CMS
- CMS中会提前处理,但并没有在老年代满之前处理掉,导致fullgc
- 继而导致hsf响应时间恶化
- 解决方案
- HSF预热
因为C1C2导致CPU高问题排查
- 查询监控
- code_cache 利用率持续升高,JVM频繁GC
- 排查思路
- 通过arthas命令
- 通过thread查看当前线程情况
- 发现有C1、C2的编译线程CPU极高
- 通过arthas命令
- 分析过程
- 当代码被频繁执行,超过1500次时触发C1,超过10000次时触发C2
- 发现当时有铺货情况,并且这条链路存在算法映射,这个里面又涉及了分词以及文本匹配逻辑,涉及放大比调用情况
- 导致了有大量待回收对象,同时也导致了C1、C2频繁的执行
- 解决方案
- 减小放大比,优化算法映射的逻辑,增加人工映射
OOM的情况
- 排查思路
- 抓取堆栈
- 使用堆栈工具排查
- 分析到有个MQ的messageList特别庞大,一直在增加
- 后续排查到是MQ的版本有bug,会导致在消费后释放的配置并不会生效,继而导致一直内存增长,未排查到的原因是因为定期有应用发布和重启,并没有发现这个情况,而且平常也没用大流量,所以也没有触发告警

