- 为什么要用消息队列
- 解耦业务逻辑,领域拆分明细
- 异步处理,快速响应用户请求
- 流量削锋
核心知识点
架构
- 架构演进
- rocketMQ 首先是一个单节点的 broker,也可以理解为一个进程开启了程序,核心能力是存储以及推送消息
- 在业务对稳定性有要求时
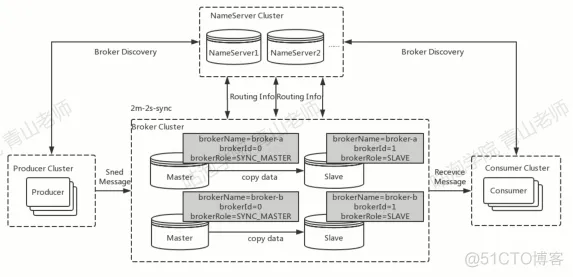
- 我们对 broker 实现了主备的机制
- 当我们流量开始增加时,单节点不再试用
- 我们就有了多节点的 broker,也就是 broker 集群
- 有了集群了,我们就需要考虑负载均衡,以及服务注册、发现机制
- 就有了 nameserver 作为注册和监听中心
- 核心角色
- 生产者【发送消息】
- 消费者【拉取消息】
- broker【消息读写的存储节点】
- nameserver【注册中心】
- 接着来聊下 topic
- 同样有 topic 的概念,但这里是一个逻辑的数据结构
- nameserver 机制
- broker 启动的时候和 nameserver 集群简历[[TCP保证机制能力]]长连接,每隔 30s 发送心跳【服务注册机制】
- 假如说 broker 挂了,怎么感知?
- nameserver 默认 10s 检查下各个 broker 最近的心跳存活时间,如果超过 120s,则剔除掉这个 broker 的路由信息
- 为什么没有用 zk 实现路由中心
- CAP 理论中,rocketMQ 重要是为了保证 AP,高可用性,放弃了强一致性;
- 怎么保证最终一致性呢?
- nameserver 间互相不通信,也没有主从,首先不用考虑他们之间的一致性
- 当新增 broker 时,默认会给所有的 nameserver 发送心跳,通过这个保证一致性
- 剔除 broker 时,可以通过 netty 进行关闭 nameserver 中的注册信息;也可以通过 120s 的存活检测进行剔除
- 另外对应发现者来说:
- 假如提供的节点一直有问题,可以做主动隔离,以及优先选择延迟低的节点
- 生产和消费者而言都需要定期拉取 nameserver 的数据
- 如果 nameserver 挂了怎么办
- 客户端中也有缓存 broker 信息,所以并不是强依赖
- Producer 发送机制
- 定时拉取 nameserver 的路由数据,然后与 broker 建立 TCP 长连接,发送到 Broker 的主节点中
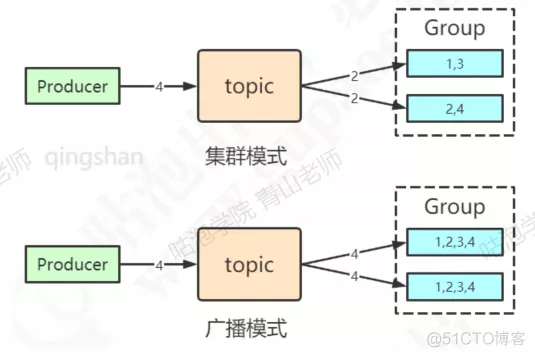
- 同时发送消息逻辑的可以组成一个 Group
- 根据 Queue 队列轮询算法,以及消息投递延迟最小的策略进行投递
- Consumer - 同样是是 nameserver 定时拉取 - 同样是相同消费逻辑的组成一个 group,这样子消息会在 Consumer 间负载 - 主子节点都是可以读取消息的,所以可以和所有节点保持连接
- 消费模式
- Pull 模式
- consumer 轮询拉取 broker 的消息
- 普通的轮询 Polling
- 数据有无更新,客户端都定时拉取数据
- 长轮询【RocketMQ 的实现方式】
- 客户端发起 Long Polling,如果服务端无数据,则 hold 住请求,回到有数据后再返回,或者超时后返回
- Push 模式
- Broker 推送消息给 Consumer
- RocketMQ 基本基于 Pull 实现,通过实现 MessageListener 接口,收到消息的时候,调用 consumerMessage 实现
- Broker 推送消息给 Consumer
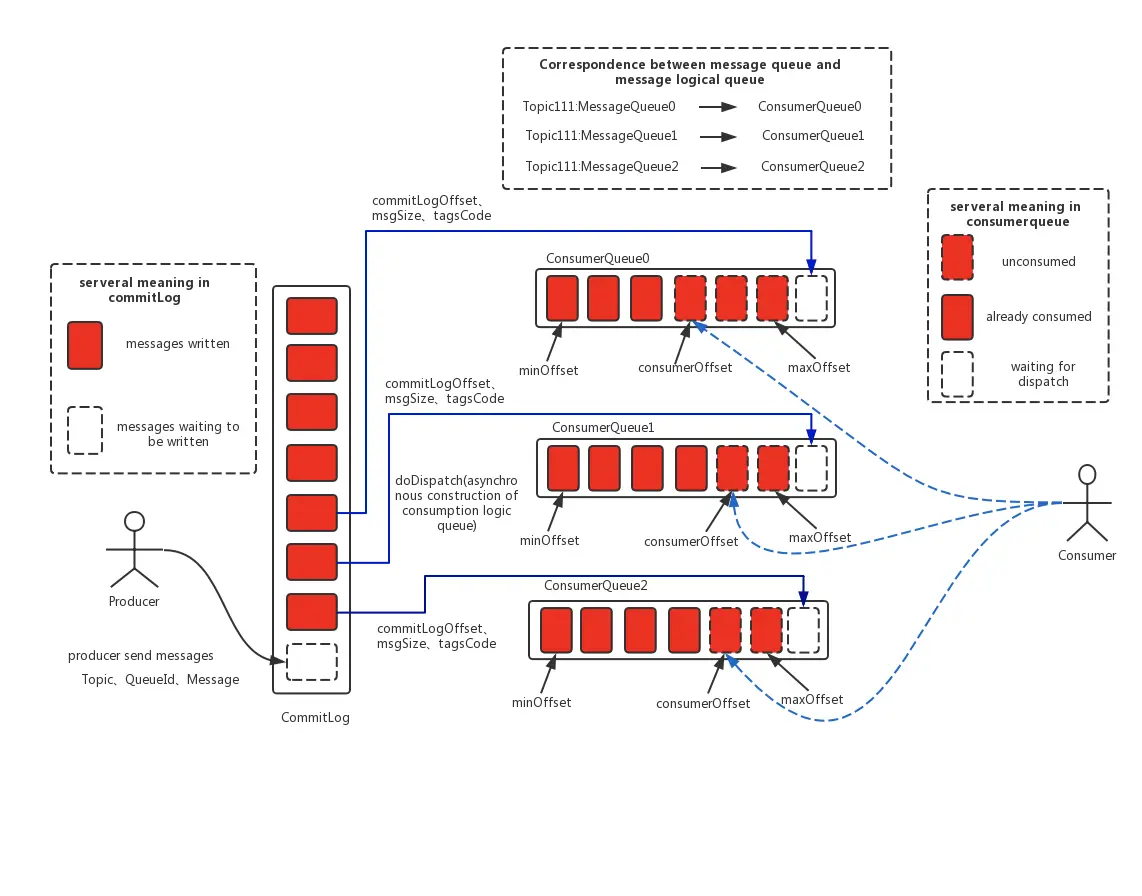
- MessageQueue
- 创建 TOPIC 时可指定生产消费队列,writeQueueNums 和 readQueueNums
- 默认是一个 topic 有 8 个队列
- Pull 模式
消息实现
如何保证全局有序消息
- 生产者顺序发送
- 写 broker 顺序写入,同时只能由一个队列
- 消费者时同样只能有一个线程进行消费
- 实现方式上
- 发送消息时指定队列的 hashKey
- 消费消息的时候,实现 MessageListenerOrderly 的实现
- 首先存储消息上是 TreeMap 实现,key 为 offset 的消息值,拉取消息时,会上锁,实现有序消费
事务消息
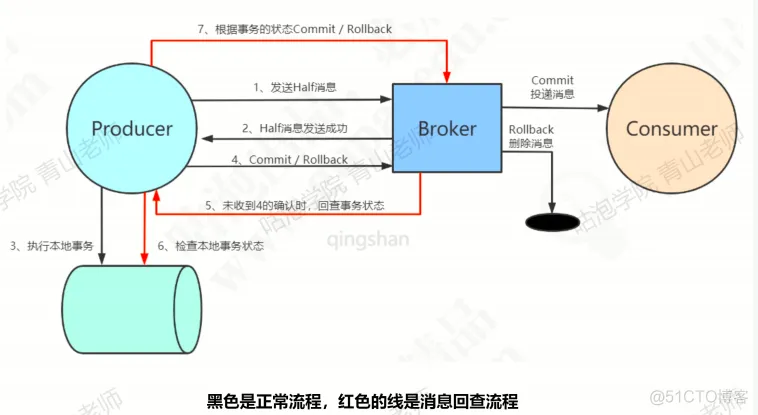 - 半事务消息 - 消费端一直消费失败 or 生产者没收到生产者返回的 ack 消息 - MQ 服务端定期扫描处于 Half 消息状态的,并咨询生产者的发送情况,是要投递还是 Rollback 丢弃消息 - 默认回查 15 次,第一次 6s,后续 60s 间隔
- 半事务消息 - 消费端一直消费失败 or 生产者没收到生产者返回的 ack 消息 - MQ 服务端定期扫描处于 Half 消息状态的,并咨询生产者的发送情况,是要投递还是 Rollback 丢弃消息 - 默认回查 15 次,第一次 6s,后续 60s 间隔延时消息 - Broker 实现一个临时存储 SCHEDULE_TOPIC_XX,通过 delay service 实现是否到期,再把消息投递到目标 topic 中 - 消费者消费消息 - 消息存储上,是实现给每个延迟级别创建任务,获取延迟时间,并创建 TimeTask,时间到了后,根据索引、topic 等重新持久化消息到 commitLog 中,并异步写入到 consume queue - 注:MQ 的消息重试也是通过延迟消息实现的,消费失败时,也会当作延迟消息投递回 broker 中
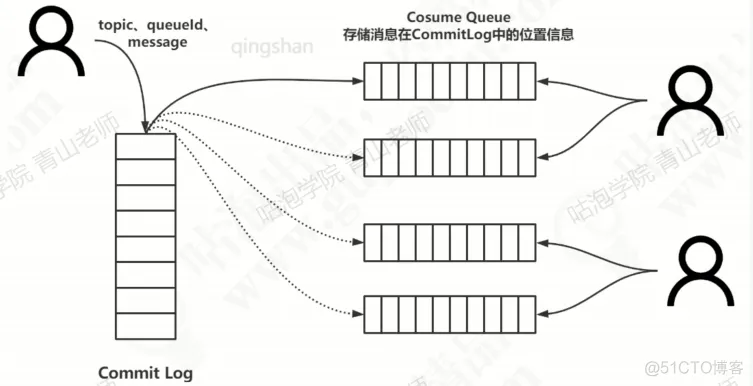
Broker 存储 - 通过集中式存储,将所有消息写在一个文件里,保证高效的顺序写 - 优点: - 队列轻量化 - 磁盘访问串行化,完全顺序写 - 消费消息时,通过 consume queue 找到消费 topic 最后一次的 offset 做存储 - 写入时候,不仅要写入 consume log,同时要把最新的 offset 写入到 consume queue 中
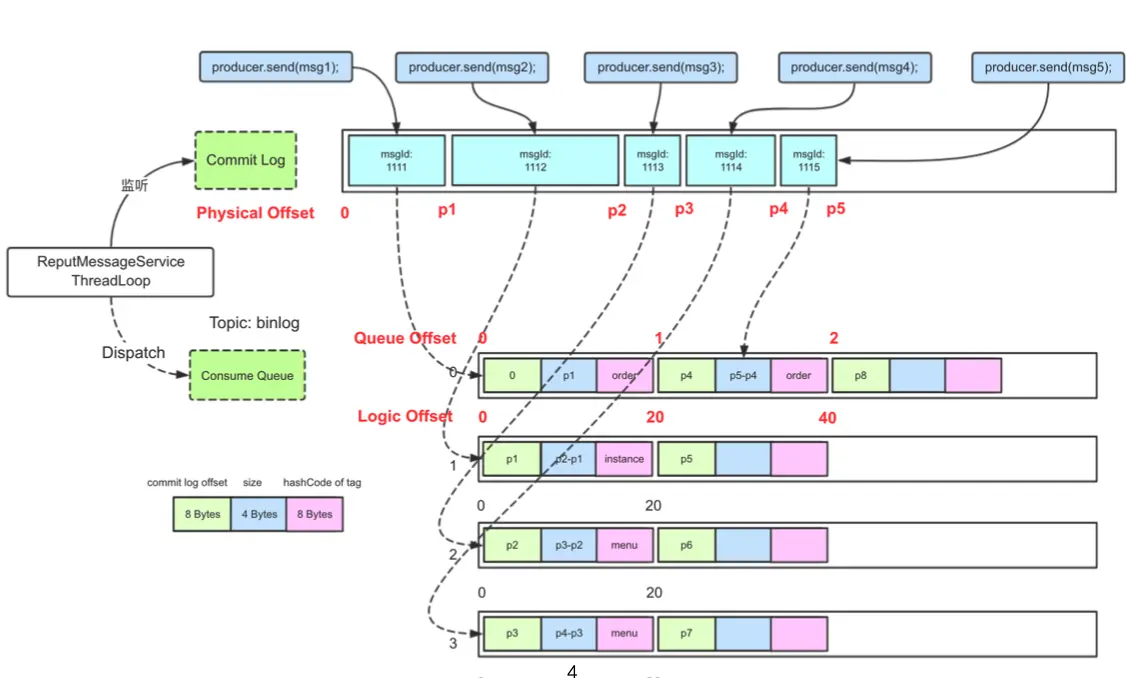
发送端发送消息的 offset 实现 - 保存在消息里的 offset 是指每个物理文件上的 offset
存储优化
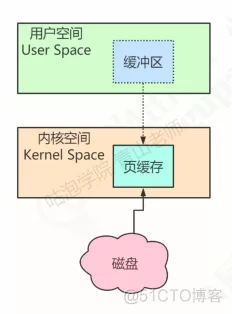
- 存储关键技术【持久化、硬盘】 - CPU 读取数据的时候,需要假如到内存中。 - 默认读取的页面大小是 4KB - 为了减少频繁磁盘 IO,可以把访问到的数据放到 Page Cache 中进行查找 - Page Cache 本身也会对文件进行预读取,同时读入紧跟的后续几个页面数据
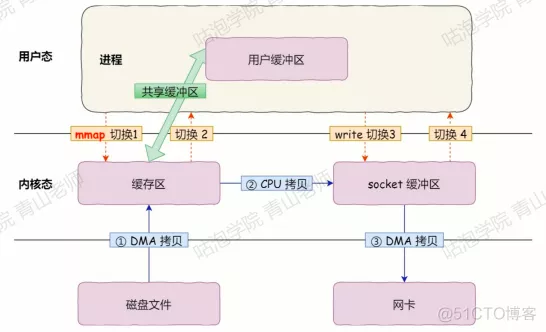
- 由于虚拟内存分为内核空间和用户空间,在这个里面还有上下文切换,拷贝的消耗,为了优化这个情况
- 通过在用户态和内核态中建立内存映射,通过指针操作 Page Cache,就不需要操作系统进行系统调用和内存拷贝
- 文件删除机制
- 超过 72 小时的文件
- 什么时候删除
- 定时任务,凌晨 4 点删除过期文件
- 磁盘超过 75%,删除过期文件
- 超过 85%时,开始批量清理文件,也不管有没有过期
- 超过 90%,禁止消息写入
高可用实现
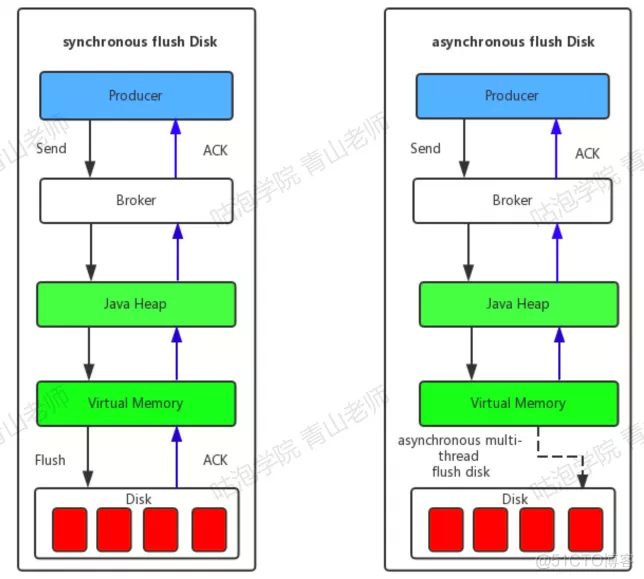
主从刷盘的实现方式 - 异步复制,可能丢失数据 - 主从同步,但吞吐量低
假如主节点挂了,怎么恢复的
- 通过 Dleger 管理,具有选主功能
- 协议上是 raft 协议
- 每个人投票时都选自己当老大,在投票结果同步完后,大家发现大家都投自己,就编成同票
- 那第二轮的时候,通过每个人的随机休眠时间,抢先醒的人就先投自己,并告诉别人,晚起来的收到别人的消息时,就决定投给他
- 如果还是不行,则重复步骤
- 同步机制上
- 分为两阶段模式,uncommitted 和 committed
- 当 leader 收到消息时,标记为 uncommitted,等 follower 同步完后,并且多数的节点都返回了 ack,则 leader 更新为 committed,再告知 follower 更新为 committed
与 kafka 区别
- kafka 性能百万 TPS、RocketMQ 十万
- kafka 采用的是异步发消息,会缓存消息进行批量发送
- 而 rocketMQ 如果也采用这个批量发送逻辑,会导致 GC 的情况,性能上承载不住
- kafka 如果超过 64 个 partition,CPU 资源变高,而 rocketMQ 可以承载 5 万个队列,CPU 没有明显变化
- 好处,队列越多,消费者的集群规模越多
- kafka 设计上是考虑日志传输,而 rocketMQ 设计上是为了解决应用间的消息传递可靠性,数据可靠性 10 个 9,服务可靠性 99.5%
- 保证数据不丢失,支持有序消息,支持分布式事务消息,支持按时间做消息回溯,支持查询迅销
- 支持消费重试
- 支持更多的 partition
场景题
OOM 排查
- 线上出现 OOM,以及 FULLGC 的情况
- 排查过程
- 通过 jmap 以及抓取 jvm 堆栈的形式,获取到了对象数量图,以及通过 headdump 工具看到当前对象堆的内容
- 是 MQ 里面的存储消息的内容
- 正常逻辑里面
- 如果 MQ 消费完成了,则会释放掉这个消息
- 但这个版本里面有个 bug,消息消费后,对象并不会释放,虽然消息消费成功了,但对象一直未释放,导致一段时间内未部署的时候,就会导致 OOM 的情况
消费速率过高
- 可以设置 pullBatchSize 或者 consumeThread 将消费速率下降
消息堆积
- 增加同个 consumerGroup 下的消费者实例,也就是应用扩容
- 增加批量消费能力
- 只处理核心逻辑,对于非核心直接跳过秒消费

