Redis 高效的内存数据库
- 为什么 redis 那么快
- 纯内存模型
- 基于 Reactor 模式设计了时间处理,依赖了单线程事件循环和 IO 多路复用实现
- 内置了大量优化的数据结构实现
- 支持丰富的数据结构
- 有灾备机制
- 有集群模式
- 有发布订阅模式,能做消息订阅,但没必要
- Lua 脚本、事务功能
- 支持惰性删除以及定期删除
缓存读写模式
旁路缓存 CacheAside
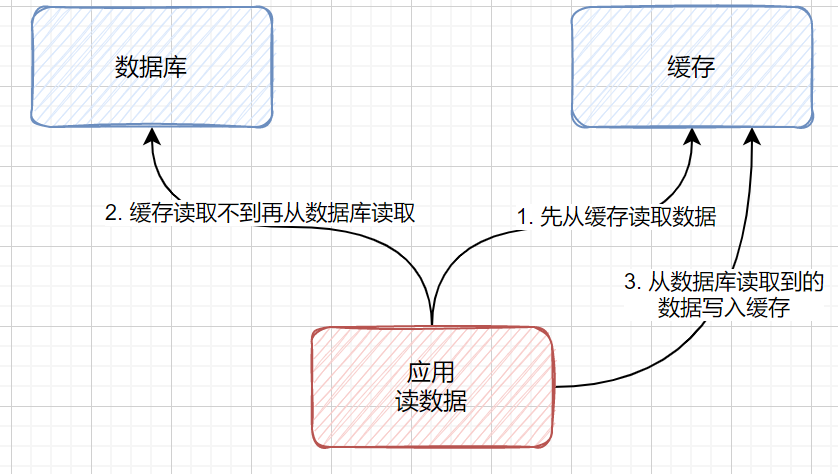
- 对于这个情况,如果要更新数据怎么实现【注,这里场景是指没有分布式锁】
- 可以先删除 cache 再更新 DB 吗?
- 不行,因为如果先删除 cache,那么正在写数据的事务,还没有更新到 DB 上,但别的读事务读的数据还是老的
- 那么反过来呢?先更新 DB 再删除 cache 呢?
- 其实也会有问题,只是因为短暂时间内 cache 会比 DB 块,所以最好的实现方式还是加分布式锁,把写的动作解耦开
- 并且提前对热点 key 进行缓存
- 可以先删除 cache 再更新 DB 吗?
读写穿透
- 都是操作 cache 先,如果不存在,则查询 DB 里的数据进行回写
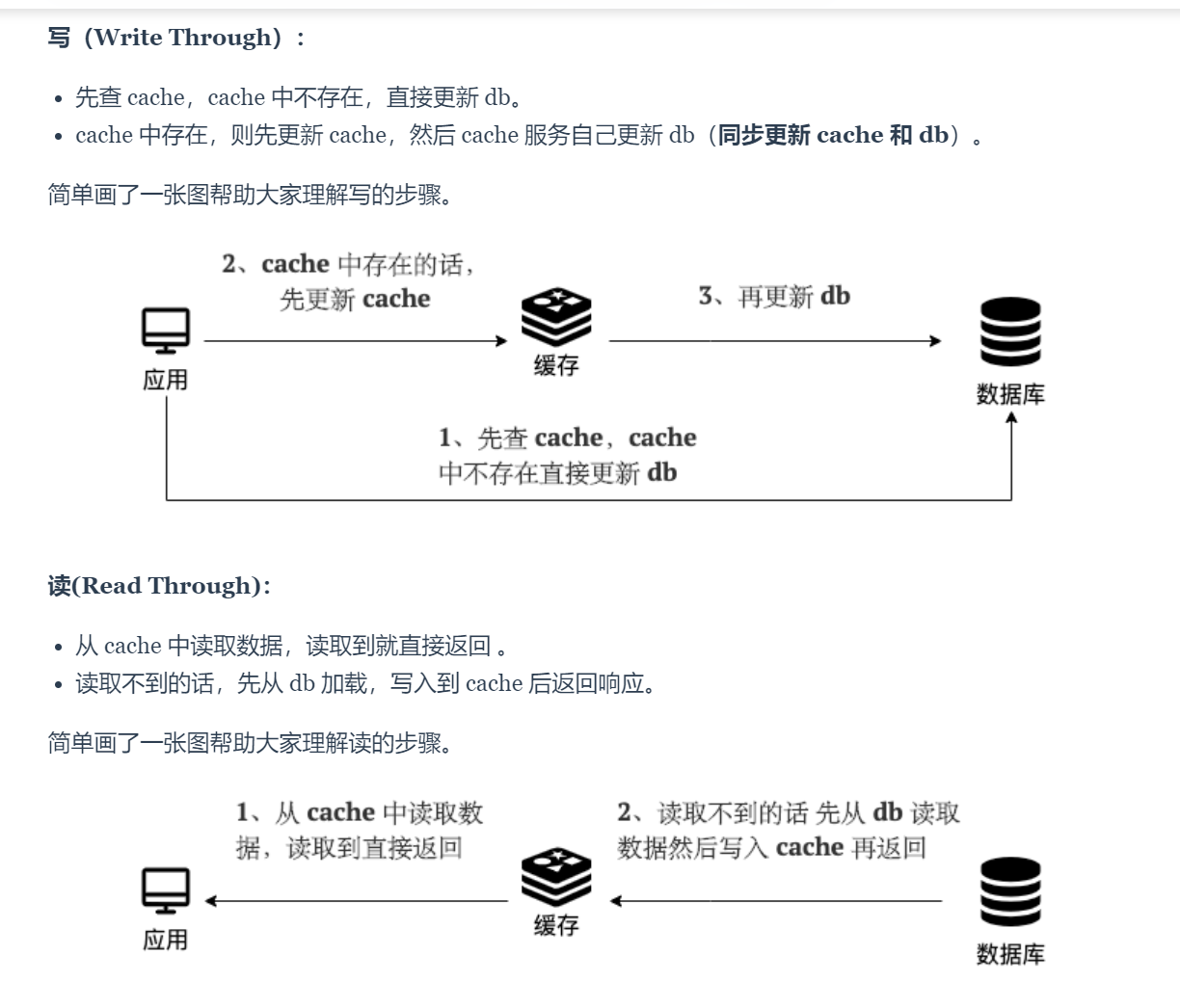
异步缓存写入
- 只操作缓存数据,DB 异步写入
- 适合数据经常变化,但一致性要求较低的,比如点赞数、游览数场景
技术实现
技术架构
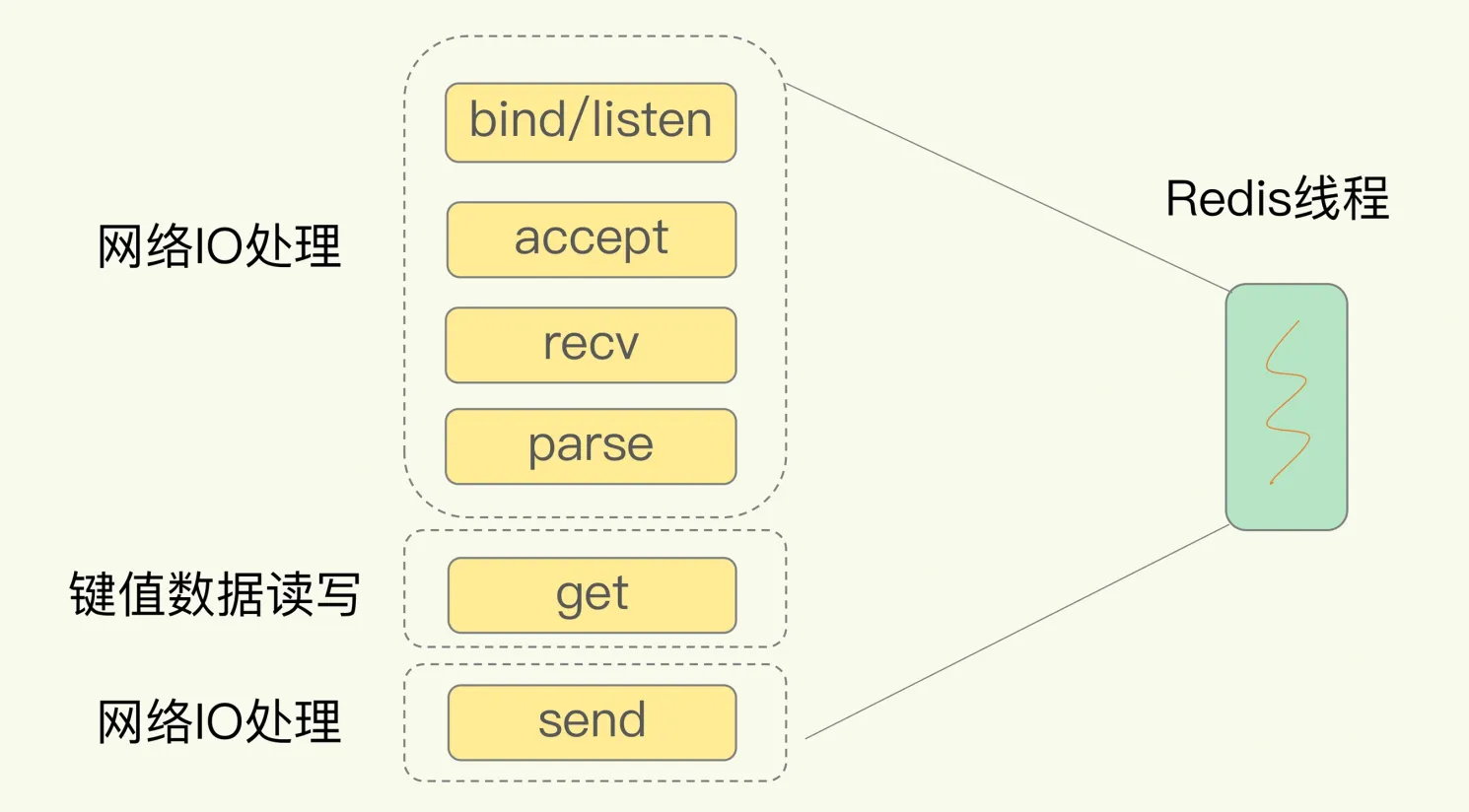
redis 单线程模型
基于 Reactor 模式开发事件处理机制,Netty 也是 - 简单来说就是为了解决 IO 阻塞等待调用,以及占用资源的问题 - 通过一个服务分发中间层,将 client 的请求转发给服务端 - 大白话解释就是 - 餐厅有多个客人,前台点菜的服务员是一个,而后面做饭的厨师有多个【当然随着业务复杂,这里面的服务员和厨师可以是 1,也可以是 n】
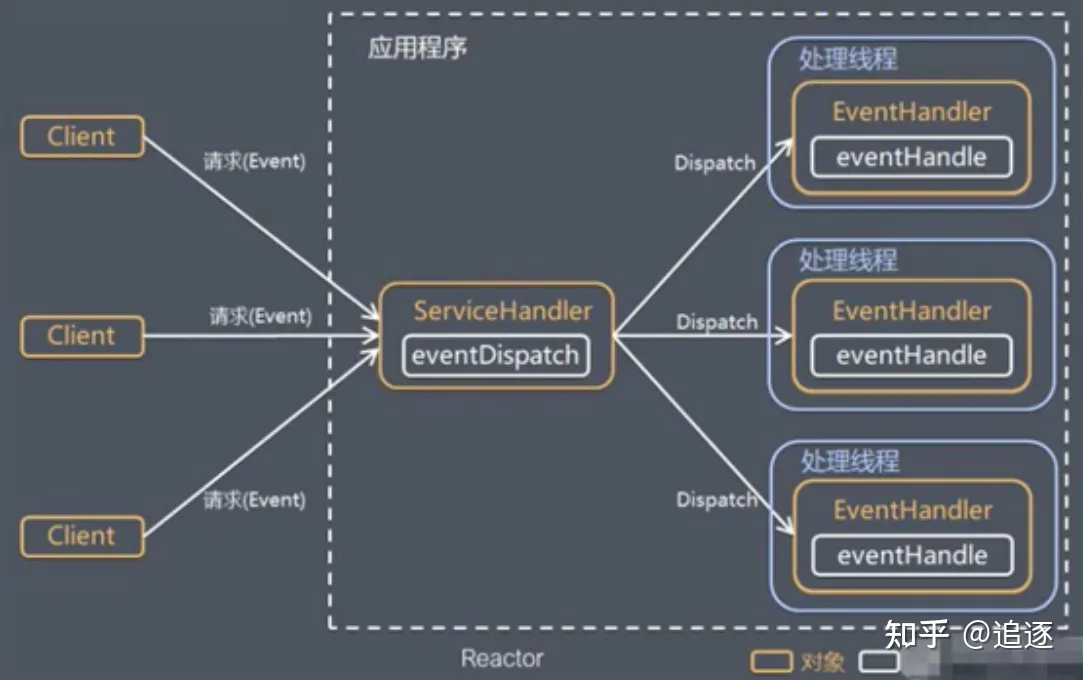
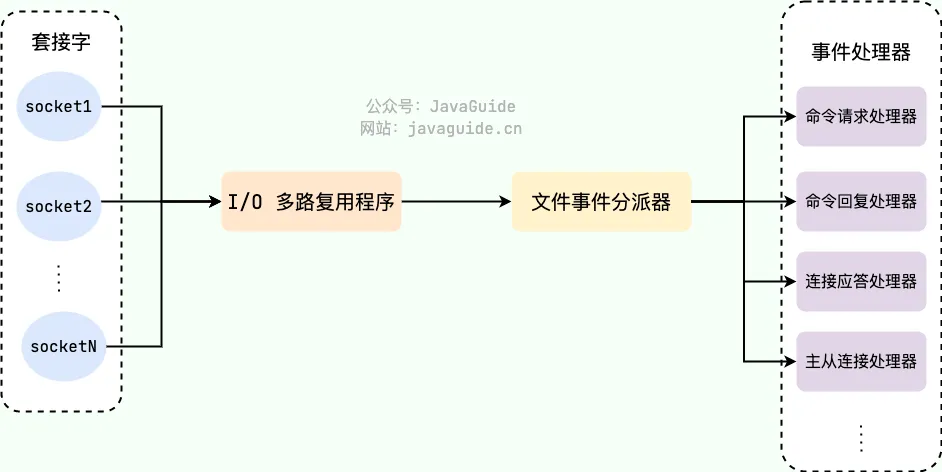
Redis 中基于 file event handler 实现,而这个是单线程实现
- 基于 IO 多路复用,监听多个套接字 socket,并根据目前执行的任务,关联不同的任务处理器
- 多个 socket 链接
- 文件事件分发机制
- IO 多路复用程序
- 事件处理器【连接应答、命令请求、命令回复】
好处 - 不需要创建多于的线程监控大量的连接,降低损耗 - 处理上是单线程,也避免了线程的上下文切换损耗 - 备注 6.0 后引入了“多线程”,主要是解决 IO 返回数据,增加数据解析协议以及返回数据的内容,但核心处理数据线程依旧是单线程的
除了这项还有什么线程在跑的
- 比如 AOF、RDB
- 惰性删除
- fsync 刷盘等
需要操作内容 - IO 处理 - 键值读写 - 网络 iO 传输
redis 内存实现
- 缓存时间
- 避免内存打爆了,及时清理不需要使用的 cache
- 怎么识别是否过期呢
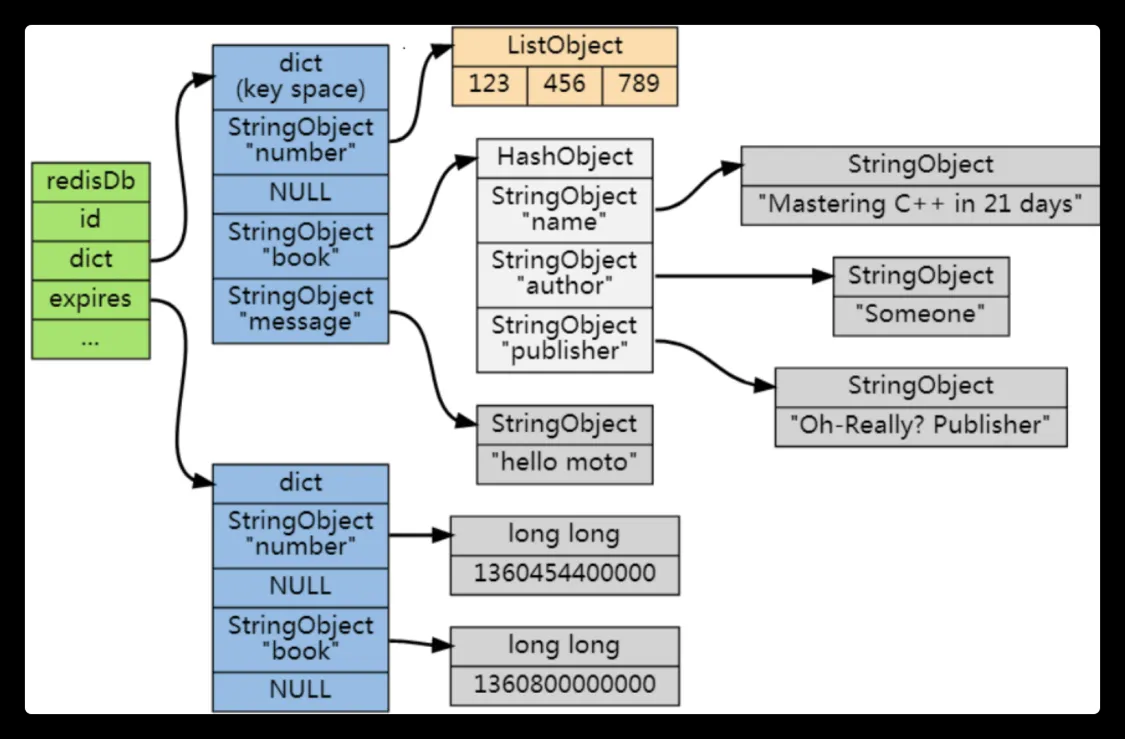
- redis 维护了一个过期字典,可以理解为 hash 表,保存数据的过期时间,UNIX 时间戳
typedef struct redisDb {
...
dict *dict; //数据库键空间,保存着数据库中所有键值对
dict *expires // 过期字典,保存着键的过期时间
...
} redisDb;
删除机制实现
- 惰性删除
- 获取 key 的时候判断是否过期
- 定期删除
- 定期删除,定期扫描 key 实现
- 怎么保证能及时删除不需要使用的内存,通过内存淘汰机制
- lru 最少最近使用
- ttl 挑选要过期淘汰
- random 从已过期的数据删除
- lru 从最近最少用的 key 删除,最常用
- random 随机
- no-eciction OOM 时报错,禁止写入,几乎没人用
事务
MULTI
SET xx xxx
EXEC
DISCARD
WATCH
- redis 的事务不支持回滚,也就是不满足 ACID 中的 A 原子性
- 认为没必要保证这个内容
- 事务是支持备份的,rdb 与 aof 都支持
- 通过 lua 脚本实现原子性功能
- 通过 lua 脚本将多条命令一次传输,减小网络开销
- 脚本可以作为一条命令执行,保证不会被其他命令插队
- 同时,如果脚本中间执行报错了,也是不会实现回滚的,所以并不能完全实现原子性操作
基础数据
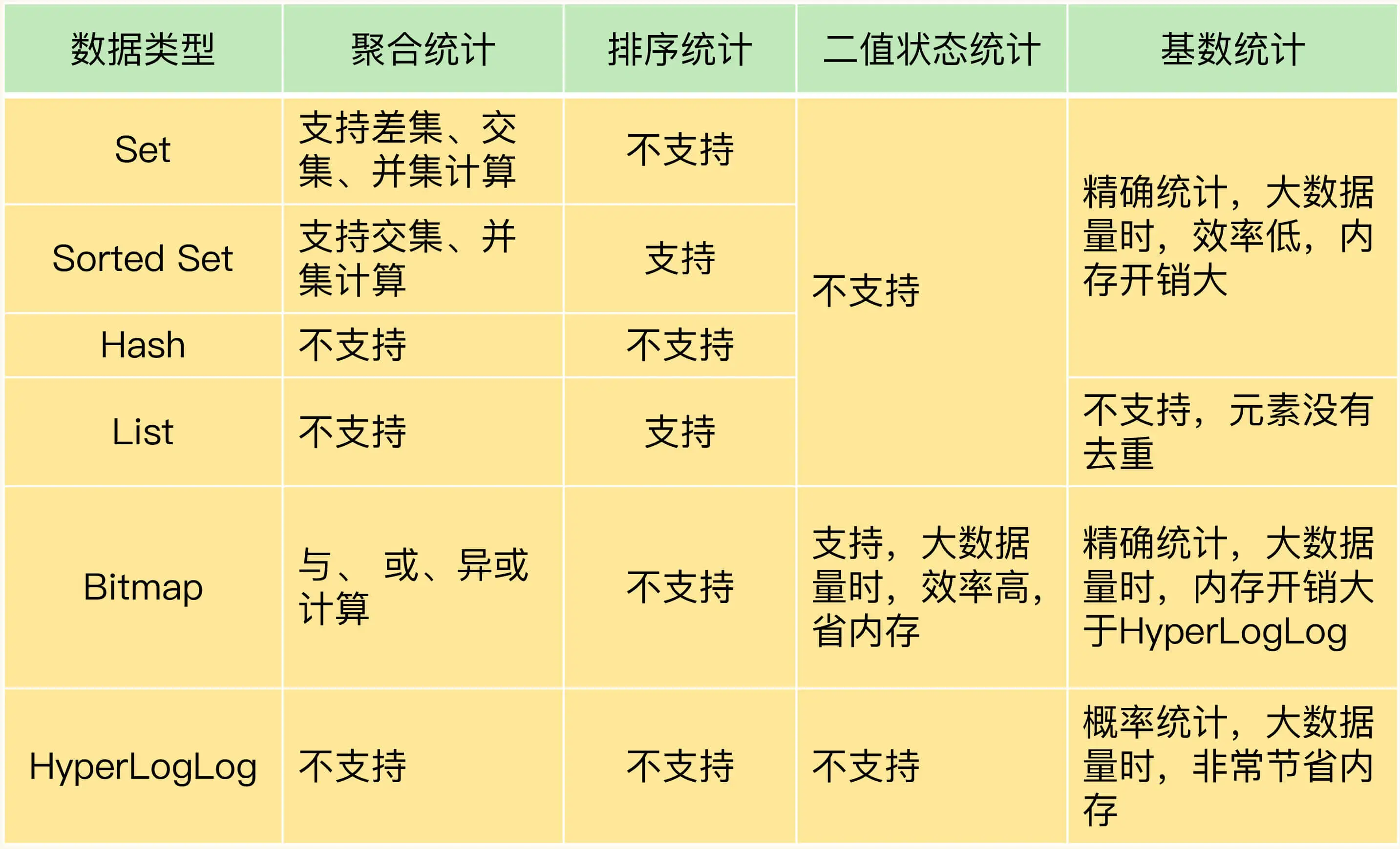
- 数据结构
- String key-val
- 实现场景:库存,微博数量,信息存储
- hash
- hashmap 的实现
- 可以用来做有主体的数据缓存,比如用户信息,商品信息
- list
- 消息列表,关注列表,公告栏列表
- 可以通过 lrange 实现分页查询功能
- set
- 实现去重的 list 功能,做一些共同关注,共同粉丝等等
- 或者说做一些防重的 key
- sortedset
- 增加 score 打分机制,可以实现礼物排行榜,弹幕等功能
- String key-val
- 底层实现
- sds simple dynamic String 除了用作字符串实现外,还作为 aof 缓冲区,用户输入缓冲区
- 记录 len
- free 未使用字节
- char 数组 buf 保存字符串
- o1 获取长度,通过 free 以及长度可以更好减少内存重分配次数
- 链表 除了 list 结构外还用于发布,订阅,监视器,客户端状态等等
- 双向,无环
- 表头指针,表尾指针
- 链表长度计数器
- 支持多态
- 字典
- 哈希键值底层实现之一,以及是数据库的增伤改查的实现
- 哈希表
- 表大小,used 已用节点
- sds simple dynamic String 除了用作字符串实现外,还作为 aof 缓冲区,用户输入缓冲区
批量操作
- 通过批量操作优化网络开销
- MGET 批量获取数据
- MSET 批量设置数据
- lua 脚本
BIGKey 优化
- 定义
- string 超过 10kb
- 复合元素超过 5000 个
- 危害
- 网络、内存占用大
- 可能造成阻塞
- 扫描
- 通过 bigkeys 命令查询,scan 所有的 key 进行查询
- 解决方案
- 拆分大 key,打散存储
- 手动清理
- lazy-free 机制
hotKEY 问题
- 如果访问过高,可能导致节点压力过大,阻塞 redis
- 通过 hotkeys 查询
- 提前预估是否存在热点 key
- 解决方案
- 二级缓存,JVM 本地
- 读写分离,从节点读取
- 打散数据
- redis cluster 实现
- cluster 搭配 65535 个槽再打散分配
慢查询
- On 的命令
- KEYS 可能导致阻塞
- HGETALL 量大
- LRANGE
- SMEMBERS
内存碎片
- 存储数据时申请的大于实际大小
- 频繁修改数据时,或者删除数据,也会导致碎片,因为这部分的内存也不会返回给操作系统
- 重启节点可恢复、或者通过自动内存碎片整理实现
Redis 内存碎片详解 | JavaGuide
持久化实现
- AOF append only file
- RDB redis database snapshot 快照
- RDB 与 AOF 混用
- RDB
- 通过 save、bgsave 的形式创建快照,获取相关数据
- 压缩的二进制文件,保存所有的数据文件,类似于 binlog
- RDB 大数据恢复时会比 AOF 快
- AOF - 开启 AOF 后,每一条命令都会写入到 AOF 缓冲区,再写到 AOF 文件中,根据 fsync 刷盘策略决定是否同步磁盘 - 同时是在执行完命令后进行重写 - 1. 避免额外检查开销,aof 的日志不会检查语法 - 2.命令执行完再记录,就不会阻塞命令的执行 - 流程 - append 写命令到 AOF 缓冲区 - write 缓冲到文件 - fsync 持久化硬盘 - rewrite 重写文件压缩命令 - load 重启宕机回复
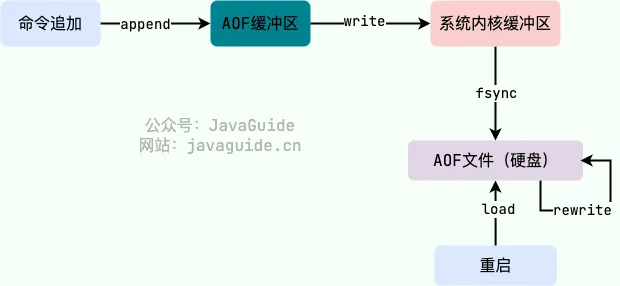
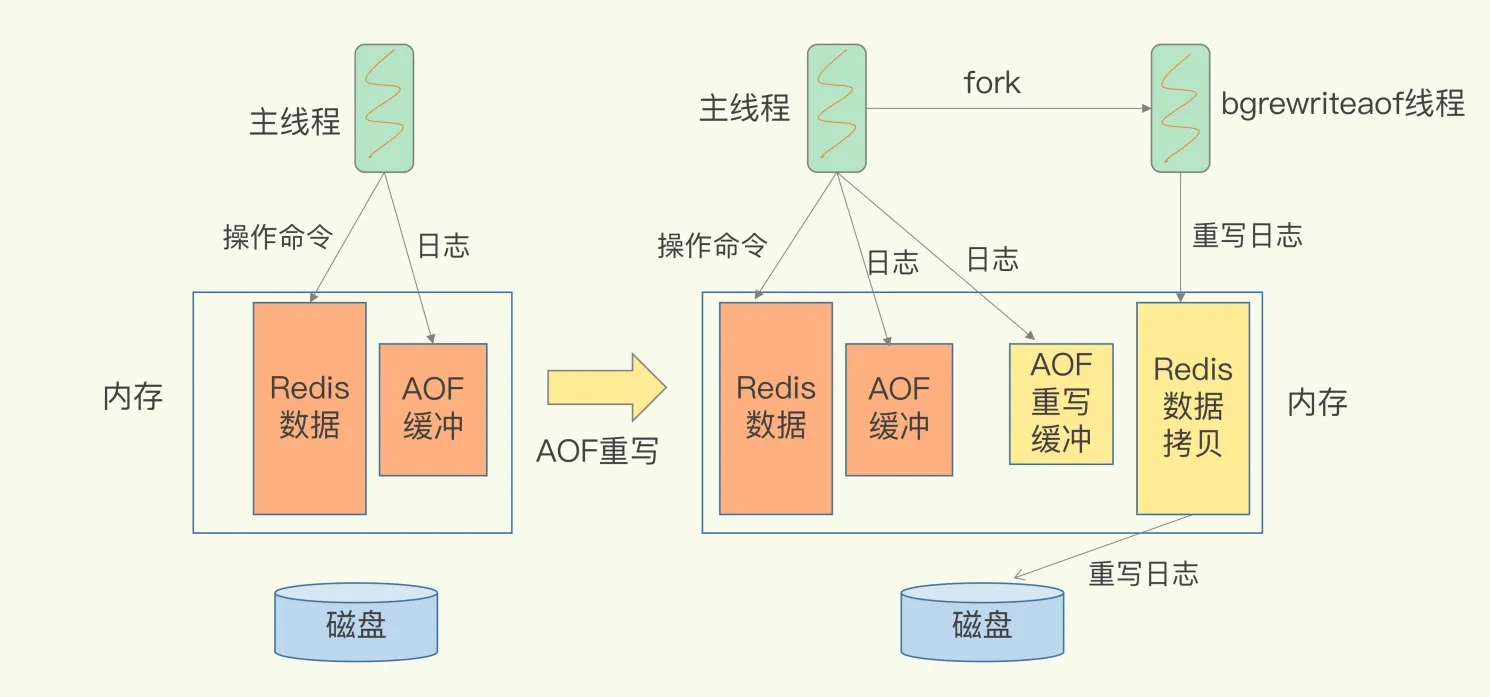
- AOF 重写 - AOF 重写是子进程中执行 - 还会有 AOF 重写缓冲区,在创建新的 AOF 文件期间,记录所有的写命令 - 当子进程完成创建新的 AOF 文件创建后,将重写缓冲区的文件追加到新的 AOF 文件后面 - 然后再用新的 AOF 文件替代旧的,保证与数据库的状态一致
宕机恢复
AOF 校验机制
- redis 启动时,校验 aof 文件,确认是否完整,通过 checksum 校验和的机制实现
- 如果发现文件不完整,则拒绝启动并报错;RDB 也有类似的机制
- 这块的原因是因为写入时,没有校验是否完整,是弱依赖的实现
场景题
购物车怎么存储
- 比如可以用 hash 结构,用户 ID 是它的 key,map 就是商品 id 和加购的商品数量
排行榜怎么做
- 通过 sorted set 实现
- 通过 zrange、zrevrange 实现正序和倒序排序,以及 zrevrank 指定元素排名
统计活跃用户怎么实现
- 通过 bitmap 实现,布谷鸟逻辑
- bitap 存储的是一个连续庞大的 01 二进制 bit 位
- key 为日期,value 为当天统计的人数
- 查询多天的数据
- bitop and desk1 20240518 20240520
- bitcount desk1 查询出来总人数
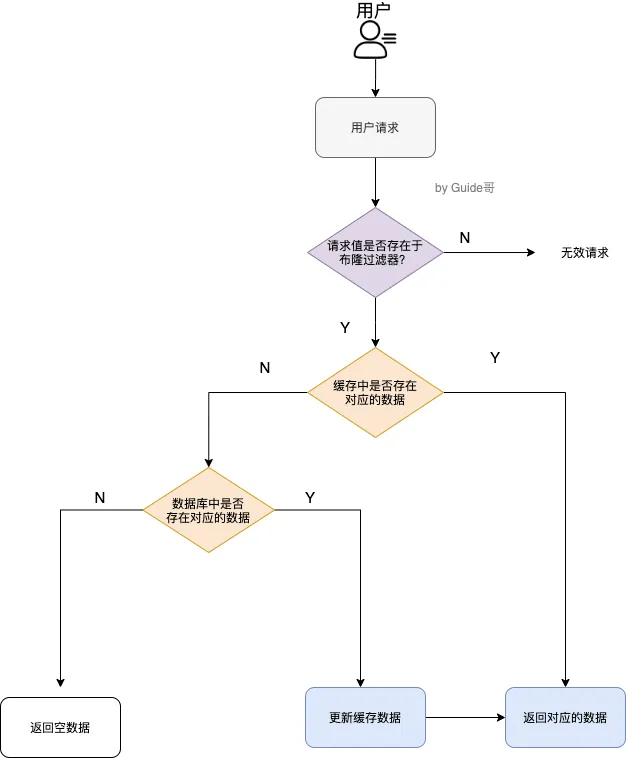
缓存穿透
- redis 没有数据,将 DB 打爆了
- 解决方案 - 提前缓存无效 key,直接返回 - 布隆过滤器 - 先判断用户在不在范围内,再决定要不要往下走
缓存击穿
- 缓存过期了,打爆了 DB
- 解决方案
- 热点 key 不失效
- 提前预热热点 key 数据
- 查询数据库的操作增加互斥锁,减少流量访问压力
缓存雪崩
- 缓存大量失效
- 解决方案
- key 失效时间随机化
- 查询增加互斥锁
- 二级缓存机制
统计亿级 keys 场景
统计页面 UV
- 可以考虑使用 hyperLogLog
- 每个 HyperLogLog 只花费 12KB 内存,就能存储 2^64 元素
- PFADD page1:uv user1 user2 user3
- PFCOUNT page1:uv
如何解决数据倾斜
- 原因
- bigKey
- Slot 分配不均
- Hash tag 倾斜
- 是指 key 里面的花括号{},计算花括号里面的 crc16 来算 key
- 解决方案
- 打散 key
- 可以手动迁移实例上的 slot 到其他节点上 cluster setslot xx importing 实例 id
如何保证秒杀场景
- 支持高并发查询
- 先通过 CRC 算法计算不同 key 对应的 slot,然后将这些打散到均匀的 key 上
- 保存库存校验以及扣减的原子性执行
#获取商品库存信息
local counts = redis.call("HMGET", KEYS[1], "total", "ordered");
#将总库存转换为数值
local total = tonumber(counts[1])
#将已被秒杀的库存转换为数值
local ordered = tonumber(counts[2])
#如果当前请求的库存量加上已被秒杀的库存量仍然小于总库存量,就可以更新库存
if ordered + k <= total then
#更新已秒杀的库存量
redis.call("HINCRBY",KEYS[1],"ordered",k) return k;
end
return 0

