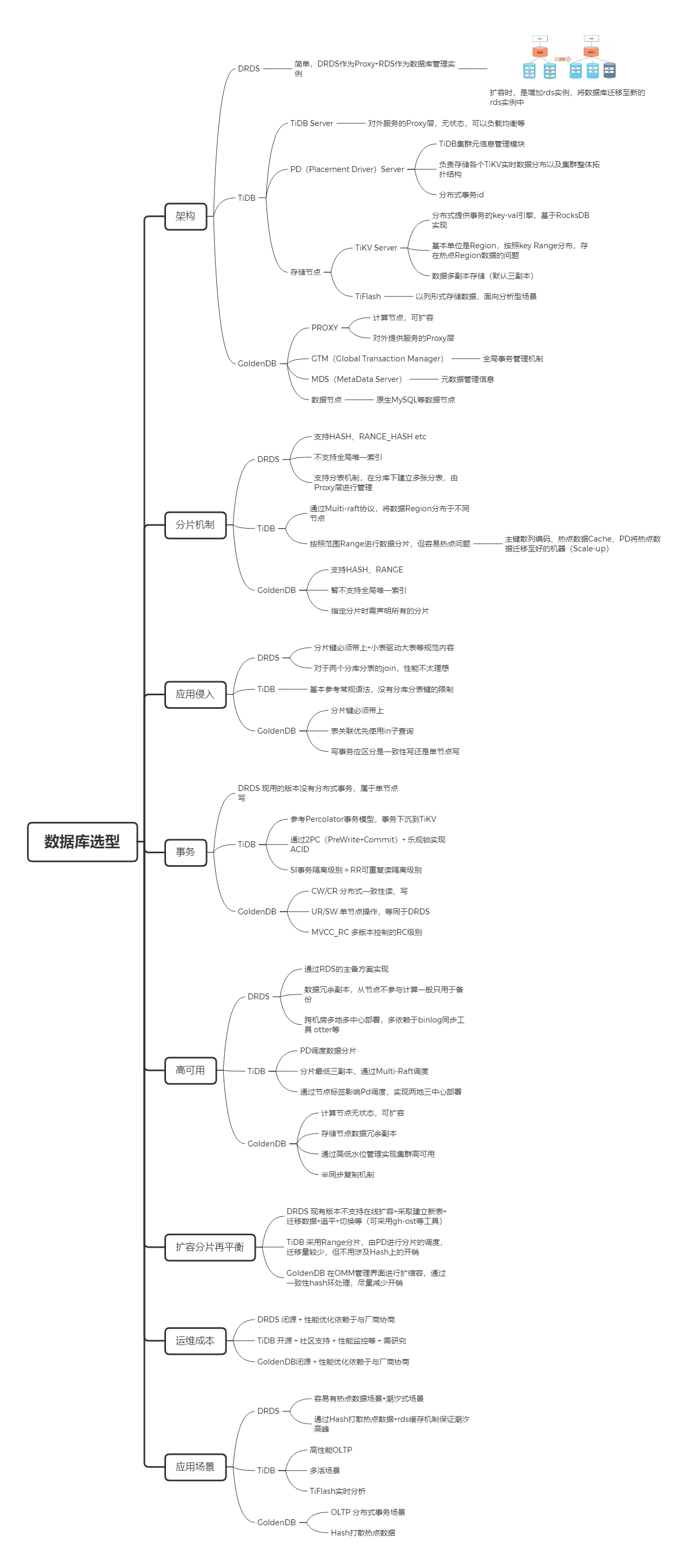
数据库分库分表
数据切分
垂直切分
基于列进行切分,若表字段过多,则可以将表拆为多个小表后,再用主键 id 进行关联
比如说学生的以往学历信息,完全可以拆到一张学历表中,再通过主键 id 进行关联
| 优点 | 缺点 |
|---|---|
| 避免热点的情况,同时拆分表的数据,减少网络和 IO 的交互,提高数据库性能 | 表没办法一次查出,对于复杂的业务场景,需要 join 或者在应用层进行关联 |
| 便于拆分各业务模块,便于管理、治理 | 分布式事务处理复杂 |
水平切分
即把数据平摊到各子表上,在各子表上设置一个代理层,通过代理层进行数据的路由,或者数据的组装
常见的方式有像 hash、date 按时间之类的进行切分数据
在阿里的推荐规范中,单表数据不宜超过 500w,如果超过了 500w,可以考虑通过 Mycat 或者引入分库分表的数据库进行数据的水平切分,亦或者说将数据转为大数据进行处理。
| 优点 | 缺点 |
|---|---|
| 数据进行水平切分后,避免了单表数据量过大,sql 查询速度慢的问题 | 水平切分后要通过分库分表键进行水平表的路由,但在 sql 复杂或者业务场景无法支持带分库分表键时,导致查询性能缓慢。 |
| 对于应用层来说,数据操作无感,前期对表设计合理的话,一般很长时间内无需改造 | 但是若数据量远超预期,而数据无法清洗时,就需要扩容,若还需要在线扩容,则扩容方案较为麻烦,导出数据,导入数据,亦或者像分表的增加等等 |
设计点
关联 join 复杂问题
对于分库分表的关联 sql join 语句复杂的问题
分库分表本质还是多个数据库的表,只是上面有层代理层帮我们处理这一堆表之间的交互,假如你的 sql 涉及到表之间的关联,但是表又带不上业务主键(分库分表键)的,就会导致 sql 缓慢
如果是单表 join 64 的分库分表,就相当于一条语句最少要执行 64 次才能得出结果,这种会给数据库带来很大的压力
解决方案:
1.1 建立广播表,让所有的分片中都有这些数据,这样子在表关联时可以直接在当前库中完成
广播表,把数据冗余到各分片上,一般只适用于小表,在直接下发指令到各分库时,能使得分库的 sql 得以关联数据执行
1.2 应用层串 join 流程
将 join 语句拆为两条 sql,在应用层组装报文,通过主键 id 和分库分表键等进行关联操作
1.3 字段冗余
字段冗余就不需要 join 了,但是这样子会导致表变大,过大可能就需要做垂直切分了
排序函数问题
排序、函数等问题(对于需跨表操作时,较为复杂)
count(*)max()min()等都需要在各分片上执行后,并汇总结果后才能得出结果,较为繁琐
分布式数据库
www
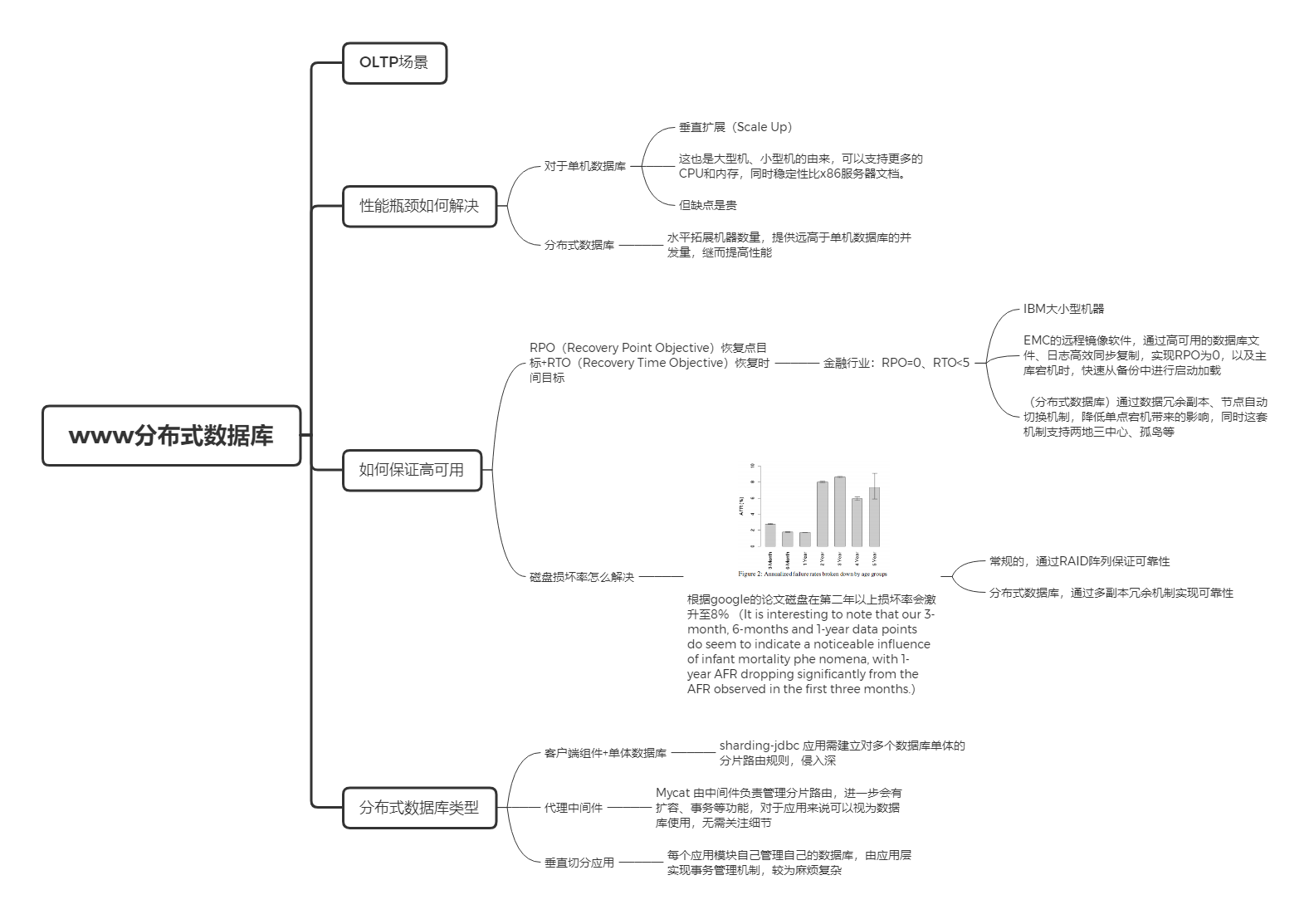
数据库选型